Building RAG Applications Without LangChain or LlamaIndex
S
NLP Intern @FutureSmart AI | Former- Scaler, ITJobxs, Speakify | ML, DL Enthusiast| Researcher - Healthcare, AI
Search for a command to run...
NLP Intern @FutureSmart AI | Former- Scaler, ITJobxs, Speakify | ML, DL Enthusiast| Researcher - Healthcare, AI
No comments yet. Be the first to comment.
Graphiti is a compact yet powerful Python library that converts raw text or JSON into an AI Knowledge Graph—a structured store of facts that acts as AI Agent Memory. Below is the exact workflow I used to load FutureSmart AI data into Neo4j, explore t...
In this blog we’ll walk through practical steps to add long‑term memory to your AI agents using Mem0 and LangGraph. We’ll build incrementally, tackling one section at a time so you can follow along and run the code as you read. Table of Contents Mem...

Retrieval-Augmented Generation (RAG) is becoming the go-to pattern for building AI systems that can fetch real-time or domain-specific knowledge on demand. But RAG alone doesn’t make your chatbot smart. With LangGraph, you can build stateful, agent-l...

Introduction In the era of advanced AI applications, Retrieval-Augmented Generation (RAG) stands out as a game-changing approach. By combining retrieval techniques with generative models, RAG enhances the quality, accuracy, and relevance of generated...

Introduction Search engines and retrieval systems have evolved to become remarkably intelligent. They no longer rely on exact keyword matches or rigid rules to find what you're looking for. Instead, they understand the context and meaning behind your...

🚀 I'm a Top Rated Plus NLP freelancer on Upwork with over $300K in earnings and a 100% Job Success rate. This journey began in 2022 after years of enriching experience in the field of Data Science. 📚 Starting my career in 2013 as a Software Developer focusing on backend and API development, I soon pursued my interest in Data Science by earning my M.Tech in IT from IIIT Bangalore, specializing in Data Science (2016 - 2018). 💼 Upon graduation, I carved out a path in the industry as a Data Scientist at MiQ (2018 - 2020) and later ascended to the role of Lead Data Scientist at Oracle (2020 - 2022). 🌐 Inspired by my freelancing success, I founded FutureSmart AI in September 2022. We provide custom AI solutions for clients using the latest models and techniques in NLP. 🎥 In addition, I run AI Demos, a platform aimed at educating people about the latest AI tools through engaging video demonstrations. 🧰 My technical toolbox encompasses: 🔧 Languages: Python, JavaScript, SQL. 🧪 ML Libraries: PyTorch, Transformers, LangChain. 🔍 Specialties: Semantic Search, Sentence Transformers, Vector Databases. 🖥️ Web Frameworks: FastAPI, Streamlit, Anvil. ☁️ Other: AWS, AWS RDS, MySQL. 🚀 In the fast-evolving landscape of AI, FutureSmart AI and I stand at the forefront, delivering cutting-edge, custom NLP solutions to clients across various industries.
In recent months, Retrieval Augmented Generation (RAG) has emerged as a powerful pattern for enhancing Large Language Models (LLMs) with private or domain-specific knowledge. While frameworks like LangChain and LlamaIndex have made RAG implementation more accessible, they can sometimes feel like black boxes, making debugging and customization challenging.
When I created a tutorial on building RAG applications with LangChain, many developers reached out with a common challenge: debugging LangChain applications was becoming increasingly difficult. The layers of abstraction, while convenient, were obscuring the underlying mechanics of how RAG actually works.
Consider these common pain points with framework-based RAG implementations:
Debugging Complexity: When something goes wrong, tracing the issue through multiple layers of framework abstraction can be time-consuming
Documentation Overhead: Understanding framework-specific concepts often requires navigating extensive documentation, taking focus away from core RAG principles
Limited Control: Framework abstractions can make it harder to customize specific components or optimize for your use case
Version Dependencies: Framework updates can introduce breaking changes or compatibility issues
In this guide, we'll build a complete RAG application from scratch using only fundamental libraries:
# Core dependencies
chromadb # Vector database for document storage
openai # LLM API access
pypdf2 # PDF document processing
python-docx # Word document processing
sentence-transformers # Text embeddings
Our implementation will include all essential RAG components:
Document Processing: Handle multiple document formats (PDF, DOCX, TXT)
Vector Storage: Implement semantic search using ChromaDB
LLM Integration: Direct interaction with OpenAI's API
Conversational Memory: Support for follow-up questions and context
By building without frameworks, you'll gain:
Deep Understanding: See how each component of RAG works and interacts
Complete Control: Customize any part of the pipeline to suit your needs
Simplified Debugging: Trace issues directly to their source
Easy Maintenance: No framework-specific knowledge required
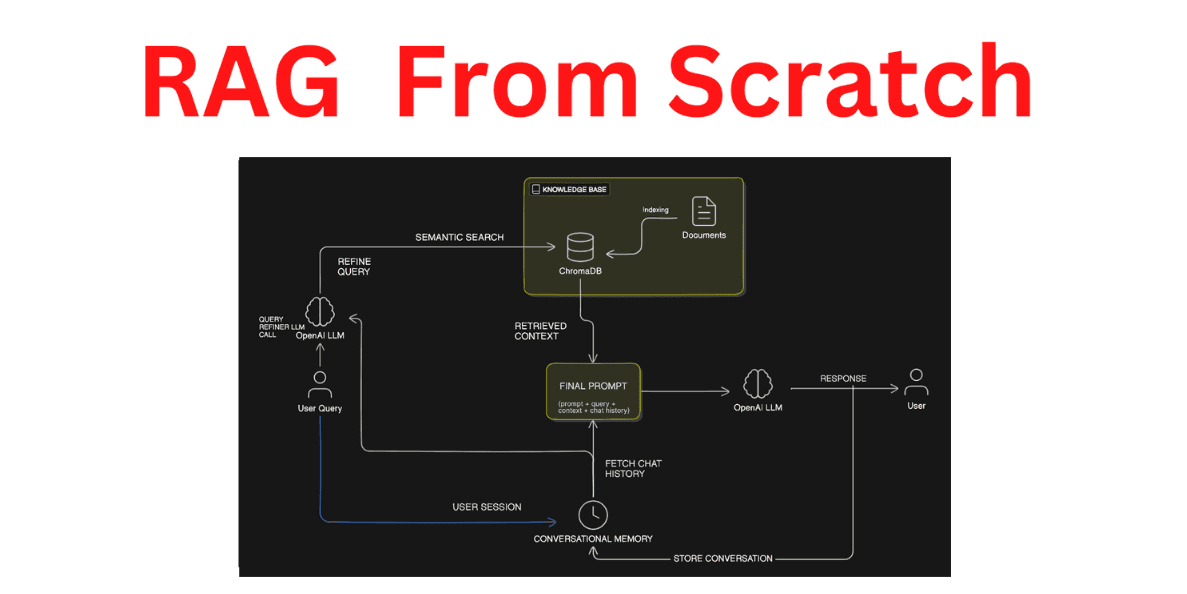
Here's a high-level overview of our architecture:

This architecture shows how we'll:
Process and index documents into our knowledge base
Handle user queries through semantic search
Maintain conversation history
Generate contextual responses
The foundation of any RAG system is its ability to process and index documents effectively. In this section, we'll build a robust document processing pipeline that can handle multiple file formats and prepare documents for semantic search.
First, let's create utilities to handle different document formats. Our implementation supports PDF, DOCX, and plain text files:
import docx
import PyPDF2
import os
def read_text_file(file_path: str):
"""Read content from a text file"""
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
def read_pdf_file(file_path: str):
"""Read content from a PDF file"""
text = ""
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
for page in pdf_reader.pages:
text += page.extract_text() + "\n"
return text
def read_docx_file(file_path: str):
"""Read content from a Word document"""
doc = docx.Document(file_path)
return "\n".join([paragraph.text for paragraph in doc.paragraphs])
We then create a unified interface for document reading:
def read_document(file_path: str):
"""Read document content based on file extension"""
_, file_extension = os.path.splitext(file_path)
file_extension = file_extension.lower()
if file_extension == '.txt':
return read_text_file(file_path)
elif file_extension == '.pdf':
return read_pdf_file(file_path)
elif file_extension == '.docx':
return read_docx_file(file_path)
else:
raise ValueError(f"Unsupported file format: {file_extension}")
Once we have the raw text, we need to split it into manageable chunks. This is crucial for two reasons:
More precise semantic search results
Staying within LLM context windows
Here's our implementation of a sentence-aware text chunker:
def split_text(text: str, chunk_size: int = 500):
"""Split text into chunks while preserving sentence boundaries"""
sentences = text.replace('\n', ' ').split('. ')
chunks = []
current_chunk = []
current_size = 0
for sentence in sentences:
sentence = sentence.strip()
if not sentence:
continue
# Ensure proper sentence ending
if not sentence.endswith('.'):
sentence += '.'
sentence_size = len(sentence)
# Check if adding this sentence would exceed chunk size
if current_size + sentence_size > chunk_size and current_chunk:
chunks.append(' '.join(current_chunk))
current_chunk = [sentence]
current_size = sentence_size
else:
current_chunk.append(sentence)
current_size += sentence_size
# Add the last chunk if it exists
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
Key features of our chunking strategy:
Preserves sentence boundaries
Configurable chunk size (default 500 characters)
Handles varying sentence lengths
Maintains readability of chunks
First, let's initialize ChromaDB with sentence transformers for embedding:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB client with persistence
client = chromadb.PersistentClient(path="chroma_db")
# Configure sentence transformer embeddings
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="all-MiniLM-L6-v2"
)
# Create or get existing collection
collection = client.get_or_create_collection(
name="documents_collection",
embedding_function=sentence_transformer_ef
)
Key components explained:
PersistentClient: Stores embeddings on disk for data persistence
all-MiniLM-L6-v2: A lightweight but effective embedding model
get_or_create_collection: Handles both initial creation and subsequent access
Now we'll create a complete pipeline that processes documents and prepares them for insertion into ChromaDB:
def process_document(file_path: str):
"""Process a single document and prepare it for ChromaDB"""
try:
# Read the document
content = read_document(file_path)
# Split into chunks
chunks = split_text(content)
# Prepare metadata
file_name = os.path.basename(file_path)
metadatas = [{"source": file_name, "chunk": i} for i in range(len(chunks))]
ids = [f"{file_name}_chunk_{i}" for i in range(len(chunks))]
return ids, chunks, metadatas
except Exception as e:
print(f"Error processing {file_path}: {str(e)}")
return [], [], []
The process_document function:
Reads the document content
Splits it into chunks
Generates unique IDs for each chunk
Creates metadata including source file and chunk number
To handle multiple documents efficiently:
def add_to_collection(collection, ids, texts, metadatas):
"""Add documents to collection in batches"""
if not texts:
return
batch_size = 100
for i in range(0, len(texts), batch_size):
end_idx = min(i + batch_size, len(texts))
collection.add(
documents=texts[i:end_idx],
metadatas=metadatas[i:end_idx],
ids=ids[i:end_idx]
)
def process_and_add_documents(collection, folder_path: str):
"""Process all documents in a folder and add to collection"""
files = [os.path.join(folder_path, file)
for file in os.listdir(folder_path)
if os.path.isfile(os.path.join(folder_path, file))]
for file_path in files:
print(f"Processing {os.path.basename(file_path)}...")
ids, texts, metadatas = process_document(file_path)
add_to_collection(collection, ids, texts, metadatas)
print(f"Added {len(texts)} chunks to collection")
Here's how to use the complete document processing pipeline:
# Initialize ChromaDB collection (we'll cover this in detail in the next section)
collection = client.get_or_create_collection(
name="documents_collection",
embedding_function=sentence_transformer_ef
)
# Process and add documents from a folder
folder_path = "/docs"
process_and_add_documents(collection, folder_path)
Example output:
Processing GreenGrow's EcoHarvest System_ A Revolution in Farming.pdf...
Added 6 chunks to collection
Processing Company_ QuantumNext Systems.docx...
Added 2 chunks to collection
Processing GreenGrow Innovations_ Company History.docx...
Added 5 chunks to collection
Processing Company_ TechWave Innovations.docx...
Added 1 chunks to collection
Processing Company_ GreenFields BioTech.docx...
Added 2 chunks to collection
Now for the core functionality - semantic search to retrieve relevant documents:
def semantic_search(collection, query: str, n_results: int = 2):
"""Perform semantic search on the collection"""
results = collection.query(
query_texts=[query],
n_results=n_results
)
return results
def get_context_with_sources(results):
"""Extract context and source information from search results"""
# Combine document chunks into a single context
context = "\n\n".join(results['documents'][0])
# Format sources with metadata
sources = [
f"{meta['source']} (chunk {meta['chunk']})"
for meta in results['metadatas'][0]
]
return context, sources
Example search usage:
# Perform a search
query = "When was GreenGrow Innovations founded?"
results = semantic_search(collection, query)
results
{'ids': [['GreenGrow Innovations_ Company History.docx_chunk_0',
'GreenGrow Innovations_ Company History.docx_chunk_4']],
'embeddings': None,
'documents': [['GreenGrow Innovations was founded in 2010 by Sarah Chen...',
'Despite its growth, GreenGrow remains committed to its original mission of ...']],
'uris': None,
'data': None,
'metadatas': [[{'chunk': 0,
'source': 'GreenGrow Innovations_ Company History.docx'},
{'chunk': 4, 'source': 'GreenGrow Innovations_ Company History.docx'}]],
'distances': [[0.3241303612288011, 0.5925477286632909]],
'included': [<IncludeEnum.distances: 'distances'>,
<IncludeEnum.documents: 'documents'>,
<IncludeEnum.metadatas: 'metadatas'>]}
ChromaDB search results contain several key components:
def print_search_results(results):
"""Print formatted search results"""
print("\nSearch Results:\n" + "-" * 50)
for i in range(len(results['documents'][0])):
doc = results['documents'][0][i]
meta = results['metadatas'][0][i]
distance = results['distances'][0][i]
print(f"\nResult {i + 1}")
print(f"Source: {meta['source']}, Chunk {meta['chunk']}")
print(f"Distance: {distance}")
print(f"Content: {doc}\n")
Search Results:
--------------------------------------------------
Result 1:
Source: GreenGrow Innovations_ Company History.docx, Chunk 0
Content: GreenGrow Innovations was founded in 2010 by Sarah Chen and Michael Rodriguez,
two agricultural engineers with a passion for sustainable farming. The company
started in a small garage in Portland, Oregon, with a simple mission: to make
farming more environmentally friendly and efficient. In its early days,
GreenGrow focused on developing smart irrigation systems that could
significantly reduce water usage in agriculture.
Result 2:
Source: GreenGrow Innovations_ Company History.docx, Chunk 4
Content: Despite its growth, GreenGrow remains committed to its original mission of
promoting sustainable farming practices. The company regularly partners with
universities and research institutions to advance the field of agricultural
technology and hosts annual conferences to share knowledge with farmers and
other industry professionals.
Result 3:
Source: GreenGrow Innovations_ Company History.docx, Chunk 3
Content: This system caught the attention of large-scale farmers across the United
States, propelling GreenGrow to national prominence. Today, GreenGrow
Innovations employs over 200 people and has expanded its operations to include
offices in California and Iowa. The company continues to focus on developing
sustainable agricultural technologies, with ongoing projects in vertical
farming, drought-resistant crop development, and AI-powered farm management
systems.
The results include:
documents: The actual text chunks
metadatas: Associated metadata (source, chunk number)
distances: Similarity scores (lower is better)
Now that we have our document retrieval system in place, let's integrate OpenAI's API to create the generation part of our RAG system. We'll focus on crafting effective prompts and managing the conversation flow.
First, let's configure the OpenAI client:
import os
from openai import OpenAI
# Initialize OpenAI client
client = OpenAI()
# Set your API key
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
The effectiveness of RAG heavily depends on how we structure our prompts. Let's create a modular prompt system:
def get_prompt(context: str, conversation_history: str, query: str):
"""Generate a prompt combining context, history, and query"""
prompt = f"""Based on the following context and conversation history,
please provide a relevant and contextual response. If the answer cannot
be derived from the context, only use the conversation history or say
"I cannot answer this based on the provided information."
Context from documents:
{context}
Previous conversation:
{conversation_history}
Human: {query}
Assistant:"""
return prompt
Let's implement the core response generation function:
def generate_response(query: str, context: str, conversation_history: str = ""):
"""Generate a response using OpenAI with conversation history"""
prompt = get_prompt(context, conversation_history, query)
try:
response = client.chat.completions.create(
model="gpt-4", # or gpt-3.5-turbo for lower cost
messages=[
{"role": "system", "content": "You are a helpful assistant that answers questions based on the provided context."},
{"role": "user", "content": prompt}
],
temperature=0, # Lower temperature for more focused responses
max_tokens=500
)
return response.choices[0].message.content
except Exception as e:
return f"Error generating response: {str(e)}"
def rag_query(collection, query: str, n_chunks: int = 2):
"""Perform RAG query: retrieve relevant chunks and generate answer"""
# Get relevant chunks
results = semantic_search(collection, query, n_chunks)
context, sources = get_context_with_sources(results)
# Generate response
response = generate_response(query, context)
return response, sources
query = "When was GreenGrow Innovations founded?"
response, sources = rag_query(collection, query)
# Print results
print("\nQuery:", query)
print("\nAnswer:", response)
print("\nSources used:")
for source in sources:
print(f"- {source}")
Query: When was GreenGrow Innovations founded?
Answer: GreenGrow Innovations was founded in 2010.
Sources used:
- GreenGrow Innovations_ Company History.docx (chunk 0)
- GreenGrow Innovations_ Company History.docx (chunk 4)
Conversational memory is crucial for RAG applications to handle follow-up questions and maintain context across interactions. We'll implement a robust system that manages conversation history and enables natural dialogue.
First, let's implement basic session management to handle multiple conversations:
import uuid
from datetime import datetime
import json
# In-memory conversation store
conversations = {}
def create_session():
"""Create a new conversation session"""
session_id = str(uuid.uuid4())
conversations[session_id] = []
return session_id
Let's implement functions to add and retrieve messages:
def add_message(session_id: str, role: str, content: str):
"""Add a message to the conversation history"""
if session_id not in conversations:
conversations[session_id] = []
conversations[session_id].append({
"role": role,
"content": content,
"timestamp": datetime.now().isoformat()
})
def get_conversation_history(session_id: str, max_messages: int = None):
"""Get conversation history for a session"""
if session_id not in conversations:
return []
history = conversations[session_id]
if max_messages:
history = history[-max_messages:]
return history
Create a formatter for the conversation history:
def format_history_for_prompt(session_id: str, max_messages: int = 5):
"""Format conversation history for inclusion in prompts"""
history = get_conversation_history(session_id, max_messages)
formatted_history = ""
for msg in history:
role = "Human" if msg["role"] == "user" else "Assistant"
formatted_history += f"{role}: {msg['content']}\n\n"
return formatted_history.strip()
For follow-up questions, we need to contextualize queries based on conversation history:
First Question : When was GreenGrow Innovations founded?
Follow up : Where is it headquartered?
contextualized_query : Where is GreenGrow Innovations headquartered?
def contextualize_query(query: str, conversation_history: str, client: OpenAI):
"""Convert follow-up questions into standalone queries"""
contextualize_prompt = """Given a chat history and the latest user question
which might reference context in the chat history, formulate a standalone
question which can be understood without the chat history. Do NOT answer
the question, just reformulate it if needed and otherwise return it as is."""
try:
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": contextualize_prompt},
{"role": "user", "content": f"Chat history:\n{conversation_history}\n\nQuestion:\n{query}"}
]
)
return completion.choices[0].message.content
except Exception as e:
print(f"Error contextualizing query: {str(e)}")
return query # Fallback to original query
def get_prompt(context, conversation_history, query):
prompt = f"""Based on the following context and conversation history, please provide a relevant and contextual response.
If the answer cannot be derived from the context, only use the conversation history or say "I cannot answer this based on the provided information."
Context from documents:
{context}
Previous conversation:
{conversation_history}
Human: {query}
Assistant:"""
return prompt
# Updated generate response function with conversation history also passed for Chatbot Memory
def generate_response(query: str, context: str, conversation_history: str = ""):
"""Generate a response using OpenAI with conversation history"""
prompt = get_prompt(context, conversation_history, query)
# print(prompt)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": prompt}
],
temperature=0,
max_tokens=500
)
return response.choices[0].message.content
Now let's create the main RAG query function that combines everything:
def conversational_rag_query(
collection,
query: str,
session_id: str,
n_chunks: int = 3
):
"""Perform RAG query with conversation history"""
# Get conversation history
conversation_history = format_history_for_prompt(session_id)
# Handle follo up questions
query = contextualize_query(query, conversation_history, client)
print("Contextualized Query:", query)
# Get relevant chunks
context, sources = get_context_with_sources(
semantic_search(collection, query, n_chunks)
)
print("Context:", context)
print("Sources:", sources)
response = generate_response(query, context, conversation_history)
# Add to conversation history
add_message(session_id, "user", query)
add_message(session_id, "assistant", response)
return response, sources
Here's how to use the complete system:
# Create a new conversation session
session_id = create_session()
# First question
query = "When was GreenGrow Innovations founded?"
response, sources = conversational_rag_query(
collection,
query,
session_id
)
print(response)
Example output:
ontextualized Query: When did GreenGrow Innovations come into existence?
Context: GreenGrow Innovations was founded in 2010 by .....
Sources: ['GreenGrow Innovations_ Company History.docx (chunk 0)', 'GreenGrow Innovations_ Company History.docx (chunk 3)', 'GreenGrow Innovations_ Company History.docx (chunk 4)']
GreenGrow Innovations was founded in 2010.
query = "Where is it located?"
response, sources = conversational_rag_query(
collection,
query,
session_id
)
print(response)
Contextualized Query: What is the location of GreenGrow Innovations?
Context: GreenGrow Innovations was founded in 2010 by Sarah Chen and Michael Rodriguez, two agricultural engineers with a passion for sustainable farming. The company started in a small garage in Portland, Oregon, with a simple mission......
Sources: ['GreenGrow Innovations_ Company History.docx (chunk 0)', 'GreenGrow Innovations_ Company History.docx (chunk 3)', 'GreenGrow Innovations_ Company History.docx (chunk 4)']
GreenGrow Innovations started in Portland, Oregon, and has since expanded its operations to include offices in California and Iowa.
This tutorial shows you how to build RAG without LangChain or LlamaIndex when you need direct control over your implementation. You'll learn to process documents, perform semantic search, and handle conversations using just ChromaDB and OpenAI's API. All code is production-ready and debuggable – no black boxes.
Case Studies: Visit FutureSmart AI Case Studies to see real-world applications of our NLP solutions
Contact Us: Have a project in mind? Reach out at contact@futuresmart.ai
Let us help you transform your business with custom AI solutions tailored to your specific needs.
Code: https://github.com/PradipNichite/Youtube-Tutorials/tree/main/Vanilla%20RAG