Deploy Chroma DB on AWS EC2
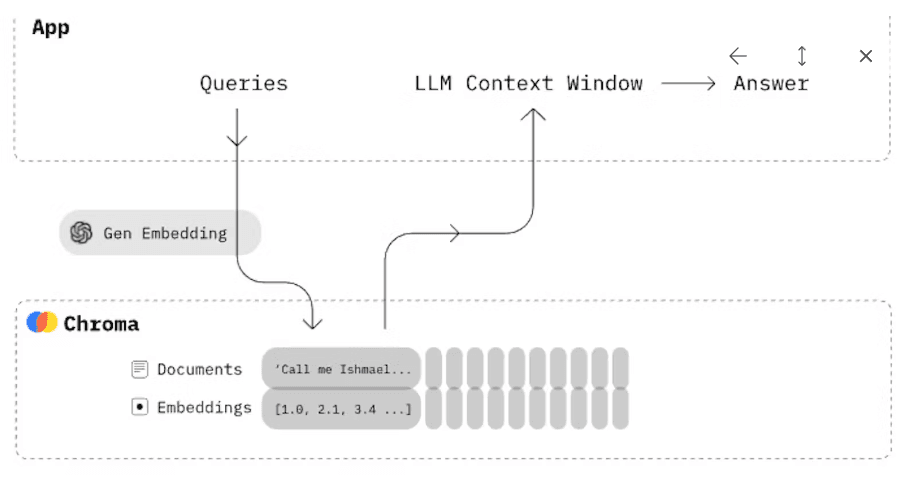
Introduction
ChromaDB, a groundbreaking tool in the world of embeddings, is reshaping semantic search with its vector database. This innovation simplifies embedding storage, management, and retrieval, while its standout feature, semantic search, offers unparalleled precision and efficiency in applications like NLP and image analysis. ChromaDB is revolutionizing the embedding landscape, ensuring seamless integration across various use cases, making it the go-to solution for those seeking a robust and efficient system for semantic search.
Note: If you're not familiar with ChromaDB and its capabilities, you can get more insights into it here.
Table of Contents:
Why we need to host chromadb?
Prerequisites and setting up
Accessing the hosted Chroma db
Managing Collections in Chroma
Adding Data to a Collection
Querying a Collection
Updating and Deleting Data in a Collection
Why do we need to host chroma db?
Accessibility: When you host ChromaDB, it becomes accessible from anywhere with an internet connection. You can access your database from your laptop, Google Colab, or multiple applications without worrying about the physical location of your data.
Collaboration: Hosting ChromaDB allows you to collaborate with others more effectively. You can share access to the hosted database with team members or collaborators, making it easier to work on a project together.
Data Synchronization: Hosting ChromaDB ensures that your data is synchronized and up-to-date. You won't need to manually update and copy-paste data folders whenever changes occur; the hosted service takes care of this for you.
Scalability: Hosting your database on a server provides the flexibility to scale resources as needed. You can accommodate larger datasets or higher traffic without worrying about the limitations of your local machine.
Data Security: Depending on the hosting service, you can benefit from enhanced security measures, such as data encryption and access controls, to protect your valuable data.
Prerequisites and setting up
To begin the setup process for utilizing Chromadb, including its installation along with Docker Compose, as well as obtaining the Chromadb repository, please follow these steps:
Set Up a Virtual Machine (VM):
Create a VM on AWS (Amazon Web Services).
Choose an instance type with sufficient RAM (e.g., 4GB or more).
Create a key pair for SSH access to the VM.
Connect to the VM:
This will allow you to connect to the EC2 instance.
ssh -i [your-key.pem] ubuntu@[your-instance-ip]Install Docker on ubuntu ec2 instance:
# Update the Package List sudo apt update # Install Required Packages sudo apt install -y apt-transport-https ca-certificates curl software-properties-common # Add the Docker Repository curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null # Install Docker sudo apt update sudo apt install -y docker-ce docker-ce-cli containerd.io # Start and Enable Docker sudo systemctl start docker sudo systemctl enable docker # verifying docker installation sudo docker --versionGet the Chroma Docker image from Docker Hub
# pulling the image sudo docker pull chromadb/chroma # running the image on port 8000 of our virtual machine sudo docker run -p 8000:8000 chromadb/chroma
Accessing the hosted Chroma db
Installing the Chroma db
!pip install chromadb
Connect to the server running in the Docker container.
import chromadb # Create a Chroma client instance chroma_client = chromadb.HttpClient(host='<our_vm_publicip address>', port=8000)This Chroma client instance will now enable seamless communication with the Chroma server, establishing the bridge between your application and the stored data.
Now the database is up at localhost at port 8000
Managing Collections in Chroma
Creating Your Collection
Collections are like data containers. You can create one like this:
# Create a collection with a special touch (embedding function)
collection = client.create_collection(name="my_collection", embedding_function=emb_fn)
Taking a Peek at Collections
Want to see what's in a collection? Easy peasy:
# Take a look at what's in the collection (don't forget the embedding function)
collection = client.get_collection(name="my_collection", embedding_function=emb_fn)
Bidding Farewell to Collections
When a collection's purpose is served, it's time to let it go:
# Say goodbye to the collection
client.delete_collection(name="my_collection")
With collections, organizing your data turns from a puzzle into a walk in the park. Stay tuned for more insights into how ChromaDB transforms data management into a delightful experience!
Adding Data to a Collection
ChromaDB lets you effortlessly inject data into your collection using the .add function. This single command can handle various types of data, making your collection richer and more informative.
Adding Raw Documents
For simple data addition, use .add with the documents parameter. ChromaDB will tokenize and embed them using your collection's default method:
collection.add(
documents=["doc1", "doc2", "doc3"],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}],
ids=["id1", "id2", "id3"]
)
Direct Embedding with Metadata
Alternatively, add documents along with their embeddings and metadata:
collection.add(
documents=["doc1", "doc2", "doc3"],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4]],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}],
ids=["id1", "id2", "id3"]
)
Linking External Vectors
If your documents are stored elsewhere, associate vectors using their IDs:
collection.add(
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4]],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}],
ids=["id1", "id2", "id3",]
)
Querying a Collection
Querying with Query Embeddings
With ChromaDB's vector database, .query simplifies semantic search. It swiftly retrieves the top closest results for your query embeddings, enhancing precision and efficiency in applications like NLP and image analysis. Discover a new level of search capabilities with ChromaDB.
collection.query(
query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2]],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains":"search_string"}
)
You can use optional filters to refine your search based on metadata or document content.
Querying with Query Texts
Alternatively, you can query using query texts. ChromaDB handles the embedding, allowing you to retrieve results based on these texts:
collection.query(
query_texts=["doc10", "thus spake zarathustra"],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains":"search_string"}
)
Updating and Deleting Data in a Collection
In ChromaDB, adapting and refining your dataset is a seamless process. With the .update and .upsert methods, you can easily modify existing entries or introduce new ones. Additionally, when it's time to trim down, ChromaDB's .delete method offers a way to remove data.
Refining with .update and .upsert
Whether it's enhancing metadata, changing embeddings, or updating documents, ChromaDB's .update method has you covered. Use it to modify specific items in the collection:
collection.update(
ids=["id1", "id2", "id3"],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4]],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}],
documents=["doc1", "doc2", "doc3"],
)
For a smarter touch, the .upsert method combines updates and additions:
collection.upsert(
ids=["id1", "id2", "id3"],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4]],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}],
documents=["doc1", "doc2", "doc3"],
)
Trimming with .delete
When it's time to clean up, the .delete method steps in. Erase items based on their IDs:
collection.delete(
ids=["id1", "id2", "id3"],
where={"chapter": "20"}
)
Remember, .delete is a powerful action that permanently removes data, so exercise caution.
In a Nutshell
Updating, adding, or removing data in ChromaDB is a breeze with these methods. Your dataset remains dynamic and tailored to your needs. Stay tuned as we further explore the versatile possibilities of ChromaDB in the upcoming sections.
Summary
Semantic Search Reinvented: Harness the Power of ChromaDB's Vector Database. Discover how ChromaDB's vector database revolutionizes semantic search, making it a breeze to find, store, and manage embeddings, and supercharging NLP and image analysis.
ChromaDB: Your Semantic Search Ally: ChromaDB's vector database streamlines embedding management, reshaping semantic search for NLP and image analysis, making it your trusted ally.
Docker Made Easy: ChromaDB + Docker = smooth sailing. We set up effortlessly for client/server teamwork.
Data Magic: Creating, adding, and exploring data collections is a cinch, giving you insights without the hassle.
Uncover Insights: Whether words or images, ChromaDB uncovers hidden gems, making your data journey transformative and exciting.
Next Step
If you're eager to learn more about using vector databases like ChromaDB to build applications with Langchain, we recommend watching this informative video tutorial.



