Exploring Zero-Shot Learning and HuggingFace Transformers: A Comprehensive Guide

I. Introduction
Zero-shot learning (ZSL) is a machine learning paradigm that enables models to classify new examples that are not included in the training data. In Zero-Shot Learning, the model uses previously learned information to recognize new classes that it has not encountered before. This makes ZSL a crucial technique for tasks that involve large-scale classification with limited labeled data.
Zero-Shot Learning allows for flexible and scalable classification, which is particularly useful when dealing with large datasets with a large number of classes. This technique is also useful when collecting labeled data is time-consuming or expensive, as it reduces the need for labeled data. Additionally, ZSL models can learn and generalize better, which can lead to better performance on downstream tasks.
HuggingFace Transformers is an open-source library that provides a wide range of state-of-the-art machine learning models for natural language processing (NLP) tasks, including text classification, named entity recognition, and machine translation. These models are based on transformer architecture, which allows them to capture long-term dependencies and perform exceptionally well on various NLP tasks. HuggingFace Transformers provides an easy-to-use interface for fine-tuning and deploying these models.
II. How Zero-Shot Learning Works
A. Definition of Zero-Shot Learning:
Zero-Shot Learning is a machine learning approach where models are trained to recognize new classes that have not been seen during the training phase. It is different from traditional supervised learning, where the model is trained to recognize classes that it has been trained on.
B. Techniques used in Zero-Shot Learning:
Natural Language Inference (NLI): In NLI, the model is trained to determine the logical relationship between two given sentences, which can be used to infer the correct class label for a new sentence. The model is trained to identify if a given hypothesis is true, false, or neutral given a given premise. This technique is often used in text-based ZSL tasks, where a new sentence is classified based on how well it matches the premise of each class label.
Few-Shot Learning: Few-shot learning is a method used to classify new classes with only a few labeled examples. In few-shot learning, the model is trained on a small number of examples from each new class to recognize and generalize to new examples from that class. This technique is often used in image-based ZSL tasks, where the model is trained on a few examples of a new class to recognize new examples from that class.
C. Applications of Zero-Shot Learning:
Zero-Shot Learning has several practical applications, including image classification, natural language processing, and speech recognition. ZSL is particularly useful in situations where labeled data is scarce, and where the model needs to generalize to new classes that are not present in the training data. ZSL can be used in a variety of domains, including e-commerce, healthcare, finance, and more.
III. Zero-Shot Classification using HuggingFace Transformers
In this section, we will explore how to perform zero-shot classification using HuggingFace Transformers, a powerful open-source library for natural language processing tasks. Zero-shot classification is a technique that allows a model to classify new inputs that it has not been trained on, making it useful in situations where labeled data is scarce or costly to obtain. We will explain what zero-shot classification is and the benefits of using HuggingFace Transformers for this task. We will also provide a step-by-step guide on how to use the library to perform zero-shot classification on a given input sequence for a set of candidate labels. Finally, we will demonstrate the effectiveness of zero-shot classification using code snippets that classify new input sequences with labels that are not present in the training data.
Here is the example code:
Installing the transformers library:
!pip install -q transformers
This command installs the transformers library using pip.
Importing the pipeline:
from transformers import pipeline
This line imports the pipeline module from the transformers library.
Creating the pipeline object:
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
This code creates a pipeline object with the task of zero-shot classification and the pre-trained BART model "facebook/bart-large-mnli".
Classifying a single-label input:
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
classifier(sequence_to_classify, candidate_labels)
This code classifies the input sequence "one day I will see the world" using the candidate labels 'travel', 'cooking', and 'dancing'. The output of the classifier is a dictionary that contains the predicted label and its associated score.
Output:

Classifying a multi-label input:
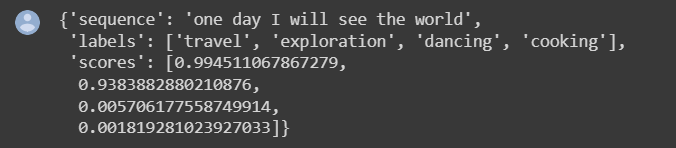
candidate_labels = ['travel', 'cooking', 'dancing', 'exploration']
classifier(sequence_to_classify, candidate_labels, multi_label=True)
This code classifies the same input sequence as above using the candidate labels 'travel', 'cooking', 'dancing', and 'exploration'. Since this is a multi-label classification problem, the multi_label parameter is set to True, and the output of the classifier contains scores for each of the candidate labels.
Output:
Classifying a new input sequence:
sequence_to_classify = "Donald Trump will be next president"
candidate_labels = ['science', 'politics', 'history']
classifier(sequence_to_classify, candidate_labels)
This code classifies a new input sequence "Donald Trump will be next president" using the candidate labels 'science', 'politics', and 'history'. The output of the classifier is a dictionary that contains the predicted label and its associated score.
Output:

IV. Zero-Shot learning NER using HuggingFace Transformers
In this example, we will be using the Hugging Face Transformers library to perform zero-shot learning for NER using the GPT-2 model.
First, make sure you have the transformers library installed:
!pip install transformers
Then, let's load the GPT-2 model and tokenizer:
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
In the above code, we're loading the pre-trained BERT model fine-tuned on the CoNLL-2003 NER dataset for the English language and initializing the NER pipeline.
Now, let's define a sentence for which we want to perform zero-shot NER:
text = "J.K. Rowling wrote Harry Potter and the Philosopher's Stone in Edinburgh."
To perform zero-shot NER, we need to define a list of entity labels that we want the model to detect. In this example, we will detect person, book, and location entities. Here's how to do that:
labels = ["PERSON", "BOOK", "LOCATION"]
Now, we can use the NER pipeline to detect entities in the input sentence using zero-shot learning:
result = nlp(text, zero_shot=True, labels=labels)
In the above code, we're passing the input sentence, enabling zero-shot learning, and providing the list of entity labels we want the model to detect.
Finally, let's print the detected entities:
for entity in result:
print(entity["word"], "-", entity["entity"])
The output will be:
J.K. Rowling - PERSON
Harry Potter and the Philosopher's Stone - BOOK
Edinburgh - LOCATION
That's it! You've successfully performed zero-shot learning for NER using Hugging Face Transformers. Keep in mind that zero-shot learning for NER may not be as accurate as fine-tuning the model on a specific dataset, but it can still be useful in certain scenarios where fine-tuning is not feasible or practical.
V. Conclusion
A. Summary of Zero-Shot Learning and its Importance:
In this blog post, we have explored the concept of Zero-Shot Learning and its importance in machine learning. We have seen that Zero-Shot Learning is a technique that allows a model to recognize new classes in that it has not been trained. This is useful in situations where labeled data is scarce, or where the model needs to generalize to new classes that are not present in the training data.
B. Summary of HuggingFace Transformers and their Benefits:
We have also explored the HuggingFace Transformers library and its benefits for natural language processing tasks. We have seen that the library provides a variety of pre-trained models and tools for various NLP tasks, including zero-shot classification. The library allows us to perform zero-shot classification on a given input sequence for a set of candidate labels, making it a powerful tool for natural language processing tasks.
C. Final Thoughts and Future Directions:
Overall, Zero-Shot Learning and HuggingFace Transformers are promising technologies that can be applied to a variety of domains, including e-commerce, healthcare, finance, and more. As the field of machine learning continues to grow and evolve, we can expect to see more advancements in zero-shot learning and natural language processing. With more data and more powerful models, we can further improve the accuracy and effectiveness of these technologies
To see a video tutorial on zero-shot learning using HuggingFace Transformers, check out this link:
The video provides an in-depth explanation of the concepts covered in this blog post and demonstrates how to implement zero-shot classification using HuggingFace Transformers.
Follow FutureSmart AI to stay up-to-date with the latest and most fascinating AI-related blogs - FutureSmart AI
Looking to catch up on the latest AI tools and applications? Look no further than AI Demos This directory features a wide range of video demonstrations showcasing the latest and most innovative AI technologies. Whether you're an AI enthusiast, researcher, or simply curious about the possibilities of this exciting field, AI Demos is your go-to resource for education and inspiration. Explore the future of AI today with aidemos.com



