GPT-4, Semantic Search, and Vector Databases: Revolutionizing Question Answering

Introduction
This blog post will delve into the revolutionary combination of GPT-4, semantic search, and vector databases, which is redefining the landscape of question-answering.
By harnessing the power of sentence transformer embeddings to index documents into vector databases, we can efficiently match user queries with relevant documents. The real magic happens when we pass these matching documents as context and the user's query to GPT-4, which intelligently processes the information to generate accurate and meaningful answers. In this blog, we will explore the underlying principles of this approach, the benefits of using GPT-4, semantic search, and vector databases in question answering, and how these technologies are shaping the future of AI-driven information retrieval.
Traditional keyword search and its limitations
Imagine you're lost in the vast expanse of the internet, trying to find a nugget of information hidden somewhere among the billions of websites out there. Earlier, you would have had to depend on conventional keyword-based search engines to retrieve this information. These engines would lookup through a corpus of documents and retrieve results that contained one or more keywords from your search query. This method has certain limitations which we will review next.
Loss of semantic meaning
Suppose you enter "raining cats and dogs" in the search bar. The keyword-based search engines provided us with all the documents that contained the words "cats," "raining," "and," and "dogs," including various cat images, rain forecasts, and so forth. However, you want to understand the meaning of an idiomatic expression referring to "heavy rainfall" in this context. Although there may be some relevant results, this approach generates a large number of false positives. It poses a serious issue because the semantic relation between words of the search query is not being determined.
Biased ranking
Some websites use tactics to include an excessive amount of keywords and phrases in their content to rank higher in search results and attract more visitors. However, these tactics can lead to biased rankings and result in websites with less relevant or even clickbait content appearing at the top of search results. This can create a frustrating and misleading experience for users
Handling ambiguous queries
When using traditional keyword-based search engines, ambiguous search queries can be a major problem. For instance, if you were to type "banks near me" into the search bar, the search engine would have trouble determining whether you are referring to the river bank or cash bank. This often forces users to refine their query and add more specific keywords to get the desired results, like "cash bank near me" in this case.
However, the search for information has undergone a major transformation in recent years with the advent of semantic search and question-answering which help us solve these problems. Today, search engines are using techniques like vector databases, embeddings, and indexing to provide users with more accurate and relevant information. So, let's delve right into these interesting topics next.
The emergence of semantic search
The emergence of semantic search has revolutionized information retrieval and has widened applications. Semantic search uses natural language processing techniques to analyze the context, intent, and relationships between words and phrases of search queries to better understand the user's query and to provide results that are not only relevant but also more comprehensive and nuanced.
Not surprisingly, it helps us solve all the problems addressed in the above section. A semantic search engine would know that "raining cats and dogs" is an idiom for heavy rainfall since it understands the contextual meaning of the query and would provide search results related to it. Also, here, the semantic similarity between the query and the document is computed to find the most relevant documents to the query rather than just matching specific keywords or phrases making it more robust and avoiding irrelevant results. The semantic search engine is also great at handling ambiguous queries and powers a lot of recommendation systems today because it generates relevant results based on the user's previous browsing behaviour and the user's intent behind the current search query. This improves flexibility and enhances the user experience
Having known the power of semantic search, let's demystify its working through practical implementation. It is highly recommended to launch an IDE and follow the code yourself while continuing to read through the rest of the article.
Sentence Embeddings: Enhancing search relevance
It is a known fact that machines understand only numerical entities. So, how do you think they are able to process sentences and phrases? This is where embeddings come into the picture. Specifically, sentence embedding is a high-dimensional vector representation of a sentence that encapsulates its meaning in a dense and continuous space. By utilizing these embeddings, we can enable machines to process natural language.
In the context of semantic search, these sentence embeddings are used to represent both the query and the documents being searched in the same latent space. The similarity between the query and documents is measured by the distance between their projected vectors. The ultimate goal of semantic search is to retrieve semantically similar documents by finding the nearest documents in the embedding space.
We will use the sentence-transformers library to generate these embeddings for us. You can install and import it by running the following commands
!pip install sentence_transformers
from sentence_transformers import SentenceTransformer
Then we instantiate a pre-trained SentenceTransformer model called 'all-MiniLM-L6-v2' which encodes a given sentence into a 384-dimensional vector representation.
model = SentenceTransformer('all-MiniLM-L6-v2')
Vector Database and Pinecone
A vector database is a database that is specifically designed to store and retrieve vector embeddings efficiently. Unlike traditional databases, which are designed to store and query structured data such as tables, a vector database focuses on the storage and retrieval of high-dimensional vectors. The benefits of using a vector database include
Faster query times: When searching for similar documents in a large dataset, traditional database systems may require scanning every document to compute the similarity between the query and each document. However, a vector database can perform such searches much faster because it uses Approximate Nearest Neighbour algorithms that allow for fast distance calculations.
Lower memory usage: Traditional databases may store documents in their original text form, which can require a lot of storage space. However, by using vector embeddings, we can represent documents in a much more compact form that requires less storage space. This not only saves disk space but also reduces the amount of memory required to perform similarity searches.
Better scalability: As the amount of data grows, traditional database systems may struggle to maintain fast query times and efficient memory usage. Vector databases, on the other hand, are designed to handle large amounts of vector data and can scale efficiently with increasing data volume.
These benefits are particularly relevant in the context of semantic search, where the number of documents and queries can be massive and where the speed of retrieval is critical for a good user experience. Pinecone is a cloud-based vector database that is designed to provide fast and scalable storage and retrieval of vector embeddings. It is particularly well-suited for use in semantic search. Let's see how we can leverage pinecone for semantic search.
For the sake of demonstrating how to insert text into the pinecone database, I have curated a sample list of three paragraphs. However, feel free to use any text data of your choice for this purpose.
text_data = ["The Great Barrier Reef, located off the coast of Australia, is the world's largest coral reef system. It is home to thousands of marine species, including fish, sharks, turtles, and dolphins. The reef also attracts millions of visitors each year, making it a significant contributor to the Australian economy. Unfortunately, the reef is under threat due to climate change, pollution, and overfishing. Efforts are being made to protect the Great Barrier Reef, such as implementing fishing restrictions, reducing pollution, and promoting sustainable tourism.",
"The iPhone, first released in 2007, revolutionized the smartphone industry. It introduced the world to the concept of a touchscreen phone with a user-friendly interface and a range of useful apps. Since then, Apple has released numerous versions of the iPhone, each with new features and improvements. The latest model, the iPhone 13, has a more powerful processor, improved camera system, and a longer battery life. Despite its popularity, the iPhone has faced criticism for its high price point and the company's approach to repairing and recycling its products.",
"Artificial intelligence (AI) is a rapidly growing field that involves the development of machines that can perform tasks that typically require human intelligence, such as recognizing speech and images, making decisions, and learning from experience. AI is being used in a wide range of industries, including healthcare, finance, and transportation. While AI has the potential to revolutionize many aspects of our lives, it also raises ethical concerns, such as the risk of bias and discrimination, privacy violations, and job displacement."]
Step-1: Create a Pinecone Index
To create a Pinecone index, you first need to sign up for a Pinecone account. Then install the pinecone-client python package by running the following command
!pip install pinecone-client -q
Then, we import the pinecone library and initialize the Pinecone API using the pinecone.init() function which accepts two parameters: api_key and environment. The api_key is a unique identifier that is used to authenticate and authorize access to the Pinecone service. The pinecone.create_index() function creates a new index in the Pinecone service with the specified indexnameand dimensionality (Here we use 384 because of the 'all-MiniLM-L6-v2' model). This index will be used to store our embeddings that can be efficiently queried using Pinecone's search functionality.
import pinecone
pinecone.init(api_key="your_api_key", environment="env")
index = pinecone.create_index("indexname", dimension=384)
index = pinecone.Index("demo")
Step-2: Loading Data into the index
First, we initialize a variable i and an empty list called upserted_data to store data that will be added or updated in the Pinecone index. Then we loop through each item in the text_data list and get the current total vector count of the index using the describe_index_stats() method. This count and variable i are used to generate the ID for the new vector that will be added to the index.
A tuple is created for each item, containing the ID of the vector, the encoded vector representation of the text data (embedding) using the all-MiniLM-L6-v2 model, and a dictionary that contains additional metadata, in this case, the content/text itself.
These tuples are then appended to the upserted_data list. Finally, the upsert() method is called with the upserted_data list passed as the vectors parameter to load the data into the Pinecone index.
upserted_data = []
i=0
for item in text_data:
id = index.describe_index_stats()['total_vector_count']
upserted_data.append(
(
str(id+i),
model.encode(item).tolist(),
{
'content': item
}
)
)
i+=1
index.upsert(vectors=upserted_data)
Step-3: Query the index
Here, we initialise a query variable to execute a semantic search and find the most related document in the database to this input query. The variable query_em stores the vector representation of the query generated by the all-MiniLM-L6-v2 model. The index.query() function is called with the query_em parameter, the top_k parameter which specifies the number of relevant search results to return, in this case, only the most relevant search result is returned and the includeMetadata parameter which specifies whether to include any metadata associated with the search results.
query = "What are some of the features of the latest iPhone model, the iPhone 13"
query_em = model.encode(query).tolist()
result = index.query(query_em, top_k=1, includeMetadata=True)
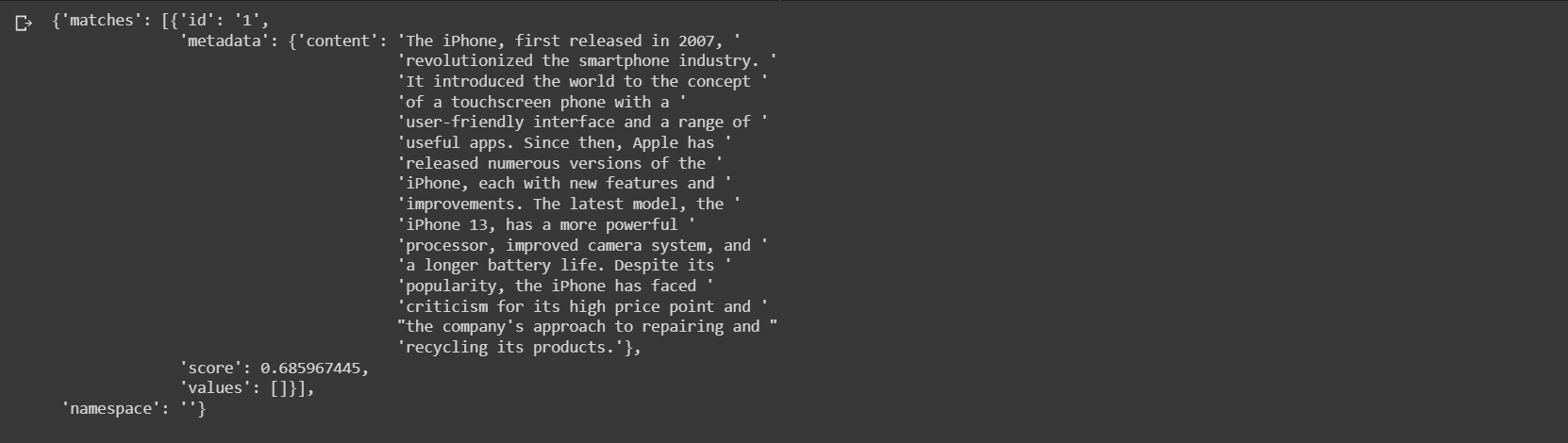
print(result)
The output is as follows. We see that the query is matched to the paragraph containing information about iPhone as expected since it is the most related document in the database
Question answering and semantic search with GPT-4
By incorporating Question Answering into Semantic Search, search engines can not only return a list of relevant documents but also extract specific answers to the user's question from those documents. This not only enhances the relevance and accuracy of search results but also provides a more satisfying search experience for the user.
One of the most recent and exciting advancements in AI is the launch of GPT-4. It is a large language model with the ability to process text and images and produce more accurate answers while handling queries more efficiently compared to its previous generations. This makes it an amazing tool for various NLP tasks including question-answering. Let's do this hands-on.
To get started, you'll first need to create an OpenAI GPT-4 API key. Then, install the openai library using the following command
!pip install openai
Next, import the openai library and set your openai key
import openai
openai.api_key = "YOUR_OPENAI_API_KEY"
The primary idea here is to utilize semantic search to retrieve the most relevant document based on a given query and then pass on it as context to a question-answering model such as GPT-4, which is capable of extracting specific information from the document. By integrating these two techniques, we can effectively extract precise and accurate answers to user queries. As we have already executed the semantic search and obtained the relevant document, we can utilize the same document as context for our question-answering model.
The system role defines the instructions for AI and indicates what task to be performed precisely. Then we make an openai.ChatCompletion request using the GPT-4 model and passing the system role and user_input in messages.
system_role="Answer the question as truthfully as possible using the provided context, and if the answer is not contained within the text and requires some latest information to be updated, print 'Sorry Not Sufficient context to answer query' \n"
context = result['matches'][0]['metadata']['content']
user_input = context + '\n' + query +'\n'
gpt4_response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role":"system","content":system_role},
{"role":"user","content":user_input}
]
)
print(gpt4_response)
The answer can be obtained in gpt4_response["choices"][0]["message"]["content"]

If you have come this far, you have one of the most powerful tools powering a lot of real-world applications like automated customer support, organizing employee accounts etc in your hand. Experiment further and build exciting applications on top of it. Check out these links for a video walkthrough of sentence embeddings and semantic search plus question answering
Follow FutureSmart AI to stay up-to-date with the latest and most fascinating AI-related blogs - FutureSmart AI
Looking to stay up to date on the latest AI tools and applications? Look no further than AI Demos This directory features a wide range of video demonstrations showcasing the latest and most innovative AI technologies. Whether you're an AI enthusiast, researcher, or simply curious about the possibilities of this exciting field, AI Demos is your go-to resource for education and inspiration. Explore the future of AI today with aidemos.com



