Langchain RAG : From Basics to Production-Ready RAG Chatbot
🚀 I'm a Top Rated Plus NLP freelancer on Upwork with over $300K in earnings and a 100% Job Success rate. This journey began in 2022 after years of enriching experience in the field of Data Science. 📚 Starting my career in 2013 as a Software Developer focusing on backend and API development, I soon pursued my interest in Data Science by earning my M.Tech in IT from IIIT Bangalore, specializing in Data Science (2016 - 2018). 💼 Upon graduation, I carved out a path in the industry as a Data Scientist at MiQ (2018 - 2020) and later ascended to the role of Lead Data Scientist at Oracle (2020 - 2022). 🌐 Inspired by my freelancing success, I founded FutureSmart AI in September 2022. We provide custom AI solutions for clients using the latest models and techniques in NLP. 🎥 In addition, I run AI Demos, a platform aimed at educating people about the latest AI tools through engaging video demonstrations. 🧰 My technical toolbox encompasses: 🔧 Languages: Python, JavaScript, SQL. 🧪 ML Libraries: PyTorch, Transformers, LangChain. 🔍 Specialties: Semantic Search, Sentence Transformers, Vector Databases. 🖥️ Web Frameworks: FastAPI, Streamlit, Anvil. ☁️ Other: AWS, AWS RDS, MySQL. 🚀 In the fast-evolving landscape of AI, FutureSmart AI and I stand at the forefront, delivering cutting-edge, custom NLP solutions to clients across various industries.
Introduction
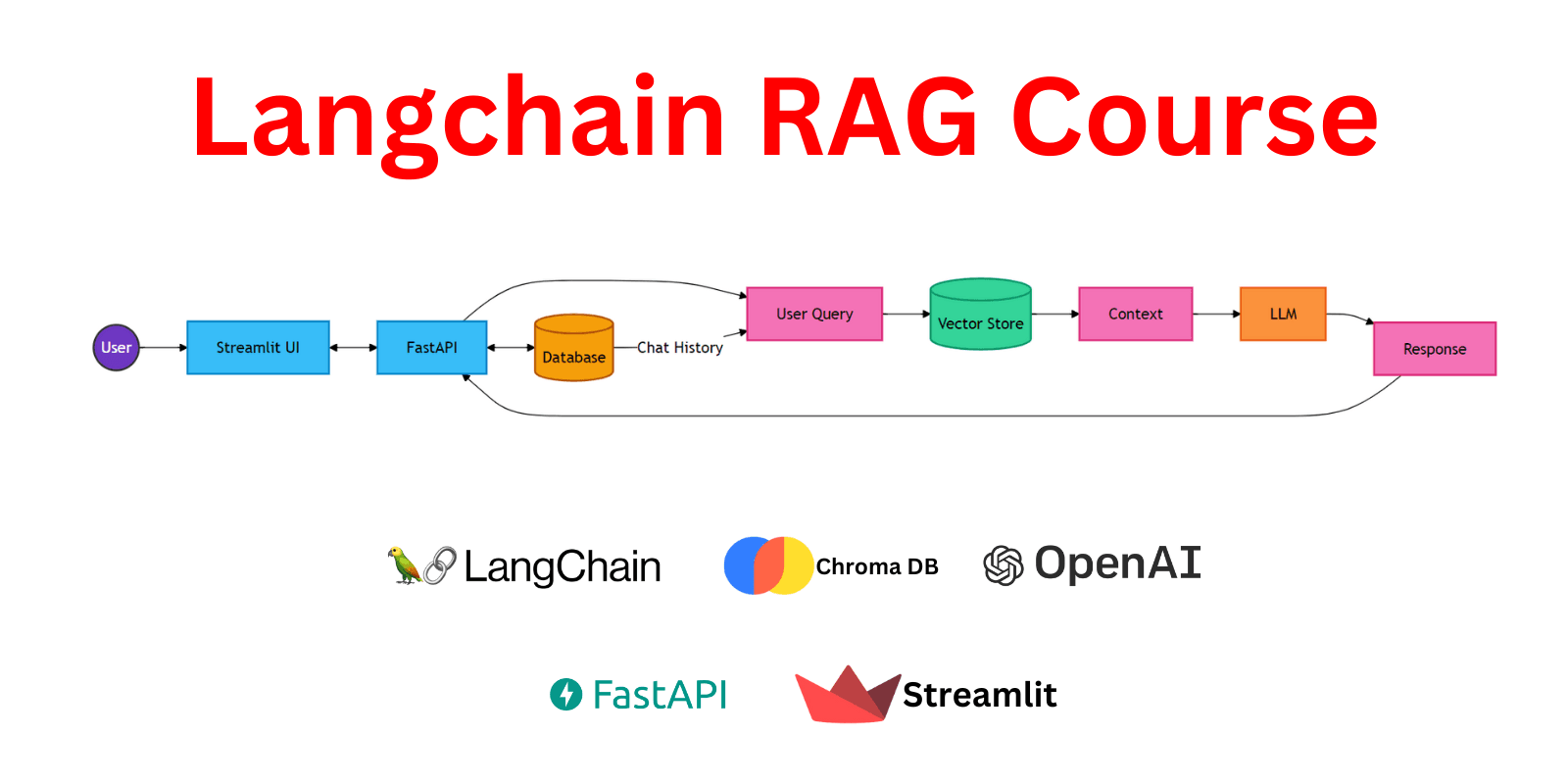
In this comprehensive guide, we'll walk you through the process of building a Retrieval-Augmented Generation (RAG) system using LangChain.
Build a production-ready RAG chatbot that can answer questions based on your own documents using Langchain. This comprehensive tutorial guides you through creating a multi-user chatbot with FastAPI backend and Streamlit frontend, covering both theory and hands-on implementation.
What You'll Learn
Introduction to RAG: Learn the fundamentals of Retrieval-Augmented Generation (RAG) and understand its significance in modern AI applications.
Working with LangChain: Get hands-on experience with LangChain, exploring its core components such as large language models (LLMs), prompts, and retrievers.
Document Processing: Master the process of splitting, embedding, and storing documents in vector databases to enable efficient retrieval.
Building RAG Chains: Develop your first RAG chain capable of answering document-based questions, and advance to creating conversational AI systems that manage complex interactions.
Contextualizing and refining queries: Learn how to refine queries using conversation history, making your AI system more accurate and responsive.
Conversational RAG: Implement a chatbot to apply these concepts practically and manage conversation history using databases.
Moving to Production: Integrate your RAG system into a FastAPI application, modularize your code, and create essential API endpoints for file management.
Building a Streamlit App: Develop a user-friendly Streamlit app that interacts with your FastAPI backend, allowing real-time data management and interaction.
What is Retrieval Augmented Generation (RAG)?
RAG is a technique that enhances language models by combining them with a retrieval system. It allows the model to access and utilize external knowledge when generating responses.
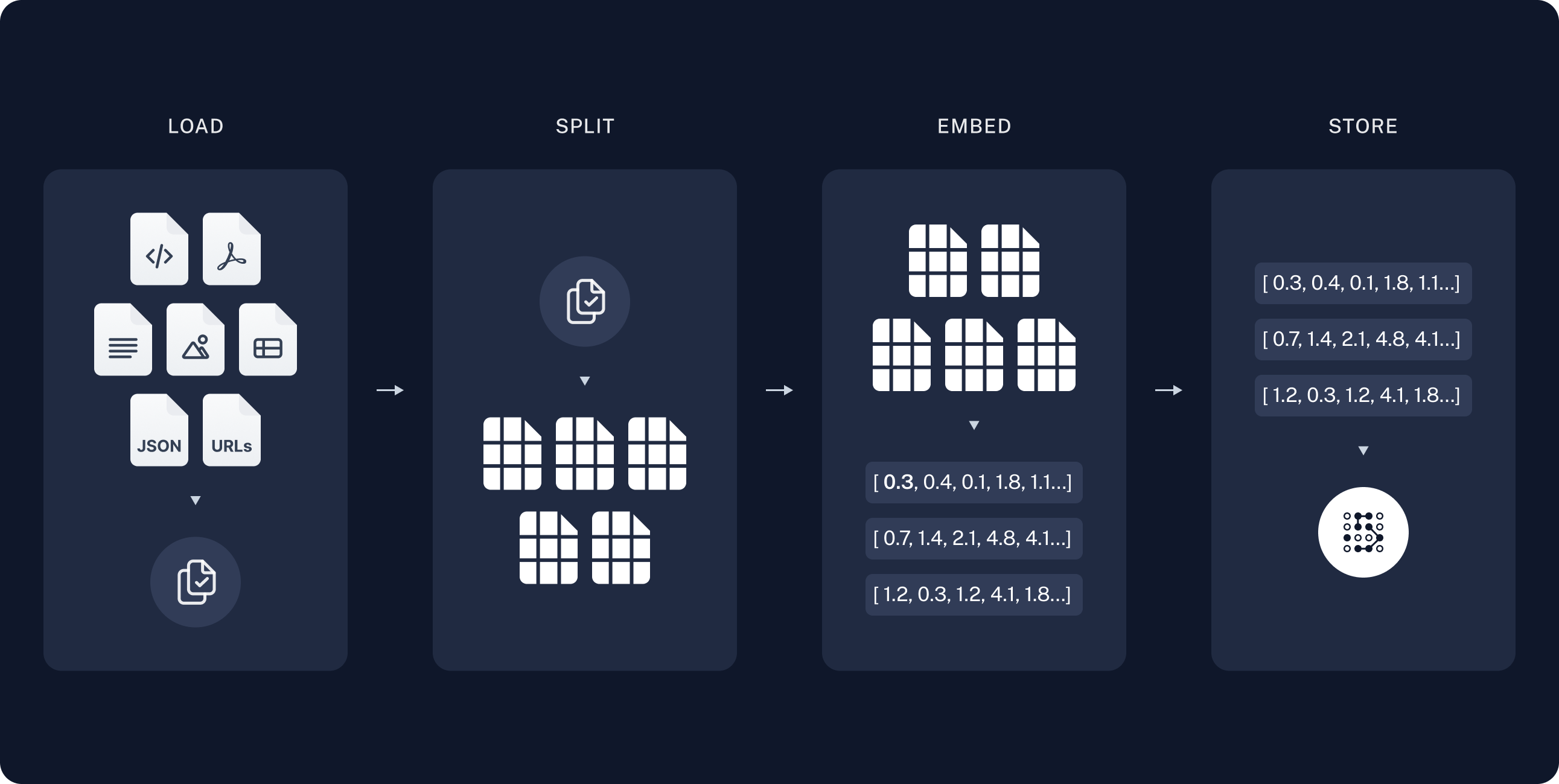
The process typically involves:
- Indexing a large corpus of documents
Source: https://python.langchain.com/docs/tutorials/rag/
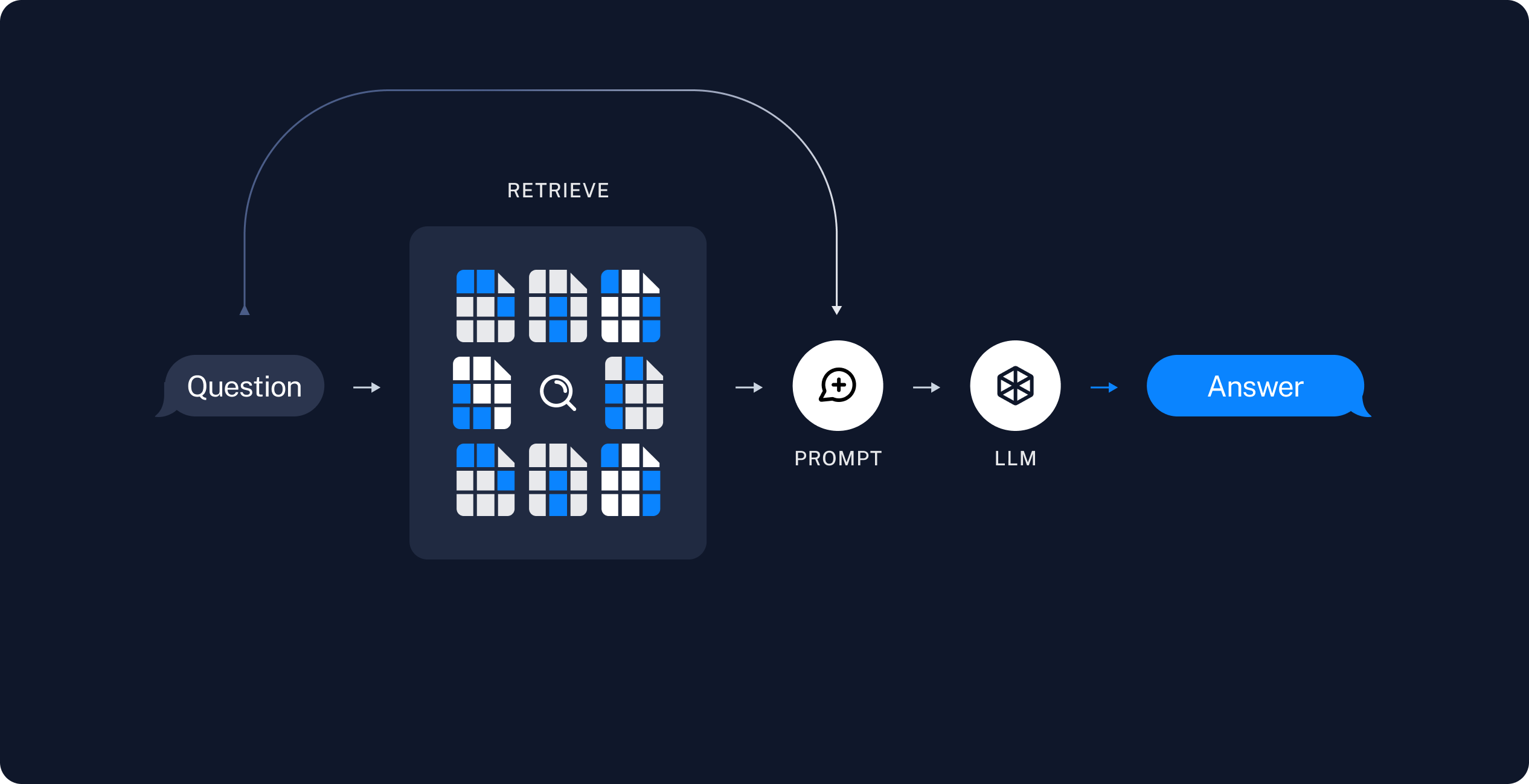
Retrieving relevant information based on the input query
Using the retrieved information to augment the prompt sent to the language model
Source: https://python.langchain.com/v0.2/docs/tutorials/rag/
Overview of Langchain
Langchain is a framework for developing applications powered by language models. It provides a set of tools and abstractions that make it easier to build complex AI applications. Key features include:
Modular components for common LLM tasks
Built-in support for various LLM providers
Tools for document loading, text splitting, and vector storage
Abstractions for building conversational agents and question-answering systems
LangChain Components and Expression Language (LCEL)
LangChain Expression Language (LCEL) is a key feature that makes working with LangChain components flexible and powerful. Let's explore how LCEL is used with various components:
1. Large Language Model (LLM)
LCEL allows direct invocation of the LLM:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
llm_response = llm.invoke("Tell me a joke")
print(llm_response)
Output:
AIMessage(content='Why did the scarecrow win an award?\n\nBecause he was outstanding in his field!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 11, 'total_tokens': 28, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_482c22a7bc', 'finish_reason': 'stop', 'logprobs': None}, id='run-78cb68a5-3613-4edb-bc3e-ff9f4b211680-0', usage_metadata={'input_tokens': 11, 'output_tokens': 17, 'total_tokens': 28, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})
2. Output Parsers
LCEL lets us chain the output parser directly to the LLM:
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
chain = llm | output_parser
result = chain.invoke("Tell me a joke")
print(result)
Output:
Why do programmers prefer dark mode?\n\nBecause light attracts bugs!
3. Structured Output
LCEL allows us to create structured output chains:
from typing import List
from pydantic import BaseModel, Field
class MobileReview(BaseModel):
phone_model: str = Field(description="Name and model of the phone")
rating: float = Field(description="Overall rating out of 5")
pros: List[str] = Field(description="List of positive aspects")
cons: List[str] = Field(description="List of negative aspects")
summary: str = Field(description="Brief summary of the review")
review_text = """
Just got my hands on the new Galaxy S21 and wow, this thing is slick! The screen is gorgeous,
colors pop like crazy. Camera's insane too, especially at night - my Insta game's never been
stronger. Battery life's solid, lasts me all day no problem.
Not gonna lie though, it's pretty pricey. And what's with ditching the charger? C'mon Samsung.
Also, still getting used to the new button layout, keep hitting Bixby by mistake.
Overall, I'd say it's a solid 4 out of 5. Great phone, but a few annoying quirks keep it from
being perfect. If you're due for an upgrade, definitely worth checking out!
"""
structured_llm = llm.with_structured_output(MobileReview)
output = structured_llm.invoke(review_text)
print(output)
print(output.pros)
Output:
MobileReview(phone_model='Samsung Galaxy S21', rating=4.0, pros=['Gorgeous screen', 'Vibrant colors', 'Insane camera quality, especially at night', 'Solid battery life'], cons=['Pricey', 'No charger included', 'New button layout can be confusing'], summary="Overall, it's a solid 4 out of 5. Great phone, but a few annoying quirks keep it from being perfect. If you're due for an upgrade, definitely worth checking out!")
['Gorgeous screen', 'Vibrant colors', 'Insane camera quality, especially at night', 'Solid battery life']
4. Prompt Templates
LCEL shines when working with prompt templates, allowing easy chaining:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("Tell me a short joke about {topic}")
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "programming"})
print(result)
Output:
Why do programmers prefer dark mode?\n\nBecause light attracts bugs!
5. LLM Messages
LCEL allows flexible message composition:
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="You are a helpful assistant that tells jokes."),
HumanMessage(content="Tell me about programming")
]
response = llm.invoke(messages)
print(response)
template = ChatPromptTemplate([
("system", "You are a helpful assistant that tells jokes."),
("human", "Tell me about {topic}")
])
chain = template | llm
response = chain.invoke({"topic": "programming"})
print(response)
Output:
AIMessage(content="Sure! Programming is the process of creating a set of instructions that a computer can follow to perform specific tasks. It involves writing code in various programming languages like Python, Java, C++, and many others. \n\nAnd speaking of programming, here's a joke for you:\n\nWhy do programmers prefer dark mode?\n\nBecause light attracts bugs!", additional_kwargs={'refusal': None}, response_metadata={...})
AIMessage(content='Sure! Here's a light-hearted joke about programming:\n\nWhy do programmers prefer dark mode?\n\nBecause light attracts bugs! \n\nIf you want to know more about programming concepts or languages, feel free to ask!', additional_kwargs={'refusal': None}, response_metadata={...})
The power of LCEL lies in its ability to chain components using the | operator and invoke them uniformly with the invoke method. This allows for easy composition of complex AI pipelines from simple, reusable components.
Document Processing for RAG Systems
After setting up our LangChain components, the next crucial step in building a RAG system is processing our documents. This involves loading the documents and splitting them into manageable chunks.
Loading Documents
We start by loading documents from various file types:
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from typing import List
from langchain_core.documents import Document
import os
def load_documents(folder_path: str) -> List[Document]:
documents = []
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
if filename.endswith('.pdf'):
loader = PyPDFLoader(file_path)
elif filename.endswith('.docx'):
loader = Docx2txtLoader(file_path)
else:
print(f"Unsupported file type: {filename}")
continue
documents.extend(loader.load())
return documents
folder_path = "/content/docs"
documents = load_documents(folder_path)
print(f"Loaded {len(documents)} documents from the folder.")
Output:
Loaded 5 documents from the folder.
This function loads PDF and DOCX files from a specified folder, converting them into a format our system can process.
Splitting Documents
Next, we split these documents into smaller, more manageable chunks:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
splits = text_splitter.split_documents(documents)
print(f"Split the documents into {len(splits)} chunks.")
Output:
Split the documents into 8 chunks.
We use a RecursiveCharacterTextSplitter to break down our documents into chunks of about 1000 characters, with a 200-character overlap between chunks. This overlap helps maintain context between chunks.
Let's examine what these documents and splits look like:
print(documents[0])
Output:
Document(metadata={'source': '/content/docs/GreenGrow Innovations_ Company History.docx'}, page_content="GreenGrow Innovations was founded in 2010 by Sarah Chen and Michael Rodriguez, two agricultural engineers with a passion for sustainable farming. The company started in a small garage in Portland, Oregon, with a simple mission: to make farming more environmentally friendly and efficient.\n\n\n\nIn its early days, GreenGrow focused on developing smart irrigation systems that could significantly reduce water usage in agriculture. Their first product, the WaterWise Sensor, was launched in 2012 and quickly gained popularity among local farmers. This success allowed the company to expand its research and development efforts.\n\n\n\nBy 2015, GreenGrow had outgrown its garage origins and moved into a proper office and research facility in the outskirts of Portland. This move coincided with the development of their second major product, the SoilHealth Monitor, which used advanced sensors to analyze soil composition and provide real-time recommendations for optimal crop growth.\n\n\n\nThe company's breakthrough came in 2018 with the introduction of the EcoHarvest System, an integrated solution that combined smart irrigation, soil monitoring, and automated harvesting techniques. This system caught the attention of large-scale farmers across the United States, propelling GreenGrow to national prominence.\n\n\n\nToday, GreenGrow Innovations employs over 200 people and has expanded its operations to include offices in California and Iowa. The company continues to focus on developing sustainable agricultural technologies, with ongoing projects in vertical farming, drought-resistant crop development, and AI-powered farm management systems.\n\n\n\nDespite its growth, GreenGrow remains committed to its original mission of promoting sustainable farming practices. The company regularly partners with universities and research institutions to advance the field of agricultural technology and hosts annual conferences to share knowledge with farmers and other industry professionals.")
And here's what a split looks like:
print(splits[1])
Output:
Document(metadata={'source': '/content/docs/GreenGrow Innovations_ Company History.docx'}, page_content="The company's breakthrough came in 2018 with the introduction of the EcoHarvest System, an integrated solution that combined smart irrigation, soil monitoring, and automated harvesting techniques. This system caught the attention of large-scale farmers across the United States, propelling GreenGrow to national prominence.\n\n\n\nToday, GreenGrow Innovations employs over 200 people and has expanded its operations to include offices in California and Iowa. The company continues to focus on developing sustainable agricultural technologies, with ongoing projects in vertical farming, drought-resistant crop development, and AI-powered farm management systems.\n\n\n\nDespite its growth, GreenGrow remains committed to its original mission of promoting sustainable farming practices. The company regularly partners with universities and research institutions to advance the field of agricultural technology and hosts annual conferences to share knowledge with farmers and other industry professionals.")
Each split maintains the original document's metadata:
print(splits[0].metadata)
Output:
{'source': '/content/docs/GreenGrow Innovations_ Company History.docx'}
This metadata helps us keep track of where each piece of information came from, which can be crucial when the AI is using this information to answer questions.
By processing our documents in this way, we're preparing the groundwork for our RAG system to efficiently retrieve relevant information when answering queries.
Creating Embeddings for RAG Systems
After processing our documents, the next crucial step is to create embeddings. Embeddings are vector representations of our text chunks that allow for efficient similarity search, which is key to the retrieval part of our RAG system.
Using OpenAI Embeddings
First, let's look at how we can create embeddings using OpenAI's embedding model:
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
document_embeddings = embeddings.embed_documents([split.page_content for split in splits])
print(f"Created embeddings for {len(document_embeddings)} document chunks.")
Output:
Created embeddings for 8 document chunks.
This code creates an embedding for each of our document chunks. The OpenAIEmbeddings class handles the interaction with OpenAI's API to generate these embeddings.
Using SentenceTransformer
Alternatively, we can use a local model with SentenceTransformer for creating embeddings:
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
document_embeddings = embedding_function.embed_documents([split.page_content for split in splits])
print(document_embeddings[0][:5]) # Printing first 5 elements of the first embedding
Output:
[0.08551725745201111, -0.07005024701356888, 0.07048681378364563, -0.023225683345198631, 0.026811434328556061]
This method uses a pre-trained SentenceTransformer model to create embeddings locally, which can be faster and doesn't require API calls.
The embeddings we've created are dense vector representations of our text chunks. Each vector typically has hundreds of dimensions (though we're only printing the first 5 here). These vectors capture semantic meaning, allowing us to find similar chunks of text by comparing their embeddings.
In our RAG system, these embeddings will be crucial for quickly finding relevant information when answering queries. When a user asks a question, we'll create an embedding for that question and then find the most similar document chunks by comparing embeddings. This allows us to retrieve the most relevant information from our document collection efficiently.
The next step will be to store these embeddings in a vector store, which will allow for fast similarity search during the retrieval phase of our RAG system.
Setting Up the Vector Store for RAG Systems
Now that we have our document embeddings, we need a way to store and efficiently search through them. This is where a vector store comes in. We'll use Chroma, a popular vector store that integrates well with LangChain.
Creating the Vector Store
Let's set up our Chroma vector store:
from langchain_chroma import Chroma
collection_name = "my_collection"
vectorstore = Chroma.from_documents(
collection_name=collection_name,
documents=splits,
embedding=embedding_function,
persist_directory="./chroma_db"
)
print("Vector store created and persisted to './chroma_db'")
Output:
Vector store created and persisted to './chroma_db'
This code creates a Chroma vector store from our document splits. It uses the embedding function we defined earlier to create embeddings for each document chunk. The vector store is then persisted to disk, allowing us to reuse it in future sessions without recomputing the embeddings.
Performing Similarity Search
Now that our vector store is set up, we can perform similarity searches. This is a key component of the retrieval process in our RAG system:
query = "When was GreenGrow Innovations founded?"
search_results = vectorstore.similarity_search(query, k=2)
print(f"\nTop 2 most relevant chunks for the query: '{query}'\n")
for i, result in enumerate(search_results, 1):
print(f"Result {i}:")
print(f"Source: {result.metadata.get('source', 'Unknown')}")
print(f"Content: {result.page_content}")
print()
Output:
Top 2 most relevant chunks for the query: 'When was GreenGrow Innovations founded?'
Result 1:
Source: /content/docs/GreenGrow Innovations_ Company History.docx
Content: The company's breakthrough came in 2018 with the introduction of the EcoHarvest System,...
Result 2:
Source: /content/docs/GreenGrow Innovations_ Company History.docx
Content: GreenGrow Innovations was founded in 2010 by Sarah Chen and Michael Rodriguez, two agricultural engineers with a passion for sustainable farming. The company started in a small garage in Portland, Oregon, with a simple mission: to make farming more environmentally friendly and efficient...
This similarity search finds the most relevant document chunks based on our query. The vector store compares the embedding of our query with the embeddings of all document chunks, returning the most similar ones.
Creating a Retriever
We can also create a retriever from our vector store, which will be useful when we build our full RAG chain:
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
retriever_results = retriever.invoke("When was GreenGrow Innovations founded?")
print(retriever_results)
Output:
[Document(...), Document(...)] # Same content as above, but in Document objects
The retriever provides a convenient interface for retrieving relevant documents, which we'll use when constructing our RAG pipeline.
By setting up this vector store, we've created a powerful tool for quickly finding relevant information from our document collection. This is a crucial component of our RAG system, enabling it to retrieve context-relevant information to support the language model's responses.
Building the RAG Chain
Now that we have our vector store set up, we can build our RAG (Retrieval-Augmented Generation) chain. This chain will retrieve relevant information and use it to generate informed responses.
Creating the RAG Chain
Let's construct our RAG chain using LangChain components:
from langchain_core.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
template = """Answer the question based only on the following context:
{context}
Question: {question}
Answer: """
prompt = ChatPromptTemplate.from_template(template)
def docs2str(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | docs2str, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
This chain does the following:
Retrieves relevant documents using our retriever.
Combines the retrieved documents into a single string.
Formats a prompt with the retrieved context and the user's question.
Sends this prompt to our language model.
Parses the output as a string.
Using the RAG Chain
Now let's use our RAG chain to answer a question:
question = "When was GreenGrow Innovations founded?"
response = rag_chain.invoke(question)
print(f"Question: {question}")
print(f"Answer: {response}")
Output:
Question: When was GreenGrow Innovations founded?
Answer: GreenGrow Innovations was founded in 2010.
Our RAG chain successfully retrieved the relevant information and used it to generate an accurate answer.
This RAG chain demonstrates the power of combining retrieval and generation. By retrieving relevant context before generating an answer, we enable our AI to provide more accurate and informed responses, especially for questions about specific information contained in our document collection.
Handling Follow-Up Questions
To make our RAG system more conversational, we need to handle follow-up questions effectively. This involves creating a history-aware retriever that can understand context from previous interactions.
Creating a History-Aware Retriever
First, let's set up the components for our history-aware retriever:
from langchain_core.prompts import MessagesPlaceholder
from langchain.chains import create_history_aware_retriever
from langchain.chains.combine_documents import create_stuff_documents_chain
contextualize_q_system_prompt = """
Given a chat history and the latest user question
which might reference context in the chat history,
formulate a standalone question which can be understood
without the chat history. Do NOT answer the question,
just reformulate it if needed and otherwise return it as is.
"""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
contextualize_chain = contextualize_q_prompt | llm | StrOutputParser()
print(contextualize_chain.invoke({"input": "Where is it headquartered?", "chat_history": []}))
Output:
Where is GreenGrow Innovations headquartered?
Now, let's create our history-aware retriever:
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
qa_prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI assistant. Use the following context to answer the user's question."),
("system", "Context: {context}"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
Using the History-Aware RAG Chain
Let's test our history-aware RAG chain with a series of questions:
from langchain_core.messages import HumanMessage, AIMessage
chat_history = []
question1 = "When was GreenGrow Innovations founded?"
answer1 = rag_chain.invoke({"input": question1, "chat_history": chat_history})['answer']
chat_history.extend([
HumanMessage(content=question1),
AIMessage(content=answer1)
])
print(f"Human: {question1}")
print(f"AI: {answer1}\n")
question2 = "Where is it headquartered?"
answer2 = rag_chain.invoke({"input": question2, "chat_history": chat_history})['answer']
chat_history.extend([
HumanMessage(content=question2),
AIMessage(content=answer2)
])
print(f"Human: {question2}")
print(f"AI: {answer2}")
Output:
Human: When was GreenGrow Innovations founded?
AI: GreenGrow Innovations was founded in 2010.
Building a Multi-User Chatbot with SQLite Storage
To make our RAG system more practical for real-world applications, we'll create a multi-user chatbot that stores conversation history in an SQLite database. This allows for persistent storage and retrieval of chat history across sessions.
Setting Up the SQLite Database
First, let's set up our SQLite database and create the necessary functions for logging:
import sqlite3
from datetime import datetime
import uuid
DB_NAME = "rag_app.db"
def get_db_connection():
conn = sqlite3.connect(DB_NAME)
conn.row_factory = sqlite3.Row
return conn
def create_application_logs():
conn = get_db_connection()
conn.execute('''CREATE TABLE IF NOT EXISTS application_logs
(id INTEGER PRIMARY KEY AUTOINCREMENT,
session_id TEXT,
user_query TEXT,
gpt_response TEXT,
model TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)''')
conn.close()
def insert_application_logs(session_id, user_query, gpt_response, model):
conn = get_db_connection()
conn.execute('INSERT INTO application_logs (session_id, user_query, gpt_response, model) VALUES (?, ?, ?, ?)',
(session_id, user_query, gpt_response, model))
conn.commit()
conn.close()
def get_chat_history(session_id):
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute('SELECT user_query, gpt_response FROM application_logs WHERE session_id = ? ORDER BY created_at', (session_id,))
messages = []
for row in cursor.fetchall():
messages.extend([
{"role": "human", "content": row['user_query']},
{"role": "ai", "content": row['gpt_response']}
])
conn.close()
return messages
# Initialize the database
create_application_logs()
This code sets up an SQLite database to store chat logs and provides functions to insert new logs and retrieve chat history.
Using the Multi-User Chatbot
Now let's use our chatbot with the SQLite storage:
# Example usage for a new user
session_id = str(uuid.uuid4())
question = "What is GreenGrow Innovations?"
chat_history = get_chat_history(session_id)
answer = rag_chain.invoke({"input": question, "chat_history": chat_history})['answer']
insert_application_logs(session_id, question, answer, "gpt-3.5-turbo")
print(f"Human: {question}")
print(f"AI: {answer}\n")
# Example of a follow-up question
question2 = "What was their first product?"
chat_history = get_chat_history(session_id)
answer2 = rag_chain.invoke({"input": question2, "chat_history": chat_history})['answer']
insert_application_logs(session_id, question2, answer2, "gpt-3.5-turbo")
print(f"Human: {question2}")
print(f"AI: {answer2}")
Output:
Human: What is GreenGrow Innovations?
AI: GreenGrow Innovations is a company founded in 2010 by Sarah Chen and Michael Rodriguez, two agricultural engineers with a passion for sustainable farming. The company specializes in developing sustainable agricultural technologies with the mission of making farming more environmentally friendly and efficient.
Conclusion: Your RAG System Questions Answered
In this guide, we've tackled the most common questions people ask when building a RAG (Retrieval-Augmented Generation) system with LangChain. Here's a quick recap of what we've covered:
"How to build a RAG system with LangChain?" We've walked through the entire process, from setting up components to creating a functional RAG chain.
"What are the key components of a LangChain RAG system?" We explored LLMs, output parsers, prompt templates, and the LangChain Expression Language (LCEL).
"How to process documents for a RAG system?" We covered loading, splitting, and preparing documents for retrieval.
"How to create embeddings for RAG?" We explained embedding creation and setting up a Chroma vector store.
"How to handle follow-up questions in RAG?" We implemented a history-aware retriever for conversational AI.
"How to build a multi-user chatbot with RAG?" We developed a scalable chatbot using SQLite for conversation history.
"What are the best practices for RAG systems?" Throughout the guide, we've shared tips and best practices for each step.
By following this guide, you now have the knowledge to build your own RAG system using LangChain. Remember, the key to great AI systems is continuous experimentation and learning.
Got questions or experiences to share? Drop them in the comments below
Check out the second part of this blog series to access the source code and data used.
FutureSmart AI: Your Partner in Custom NLP Solutions
At FutureSmart AI, we specialize in building custom Natural Language Processing (NLP) solutions tailored to your specific needs. Our expertise extends beyond RAG systems to include:
Natural Language to SQL (NL2SQL) interfaces
Advanced document parsing and analysis
Custom chatbots and conversational AI
And much more in the realm of NLP and AI
We've successfully implemented these technologies for various industries, helping businesses leverage the power of AI to enhance their operations and user experiences.
Interested in Learning More?
Check out our case studies: FutureSmart AI Case Studies Explore real-world applications of our NLP solutions and see how they've transformed businesses across different sectors.
Get in touch: Have a project in mind or want to discuss how NLP can benefit your business? We'd love to hear from you! Contact us at contact@futuresmart.ai
Whether you're looking to implement a RAG system like the one we've built in this tutorial, or you have more specific NLP needs, our team at FutureSmart AI is here to help turn your AI aspirations into reality.



