Building your own LLM RAG chatbot with Neo4j and Langchain
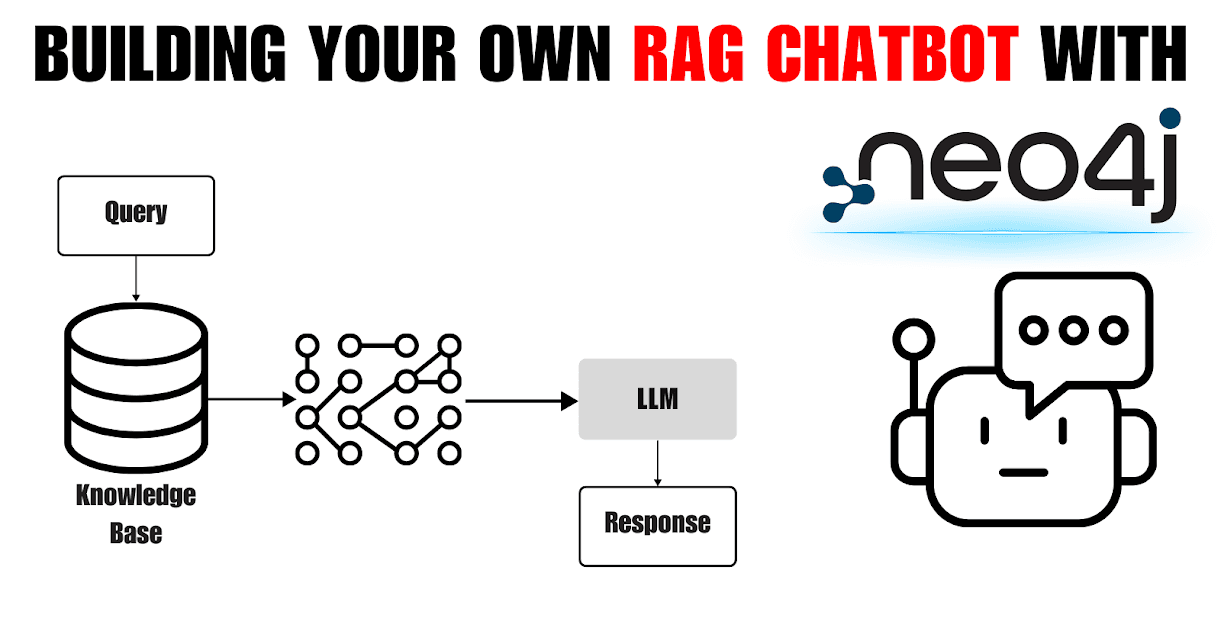
Introduction
Chatbots have become increasingly prevalent, yet traditional models often falter when faced with complex queries or natural language variations, leading to unsatisfactory user experiences. Retrieval-augmented generation (RAG) chatbots offer a significant advancement by combining the capabilities of large language models (LLMs) and knowledge graphs, enabling more natural and informative conversations.
In this blog post, we will guide you through the process of building your own RAG chatbot utilizing Neo4j as a vector store, Langchain for constructing the natural language processing (NLP) pipeline,and OpenAI's LLMs for text generation. You will gain insights into leveraging these cutting-edge technologies to develop a sophisticated chatbot that can comprehend intricate queries and provide contextual, up-to-date responses.
Discover the advantages of employing Neo4j's graph database for efficient knowledge retrieval and explore how Langchain streamlines the integration of various NLP components. Whether you are a developer seeking to enhance your chatbot's capabilities or an enthusiast exploring conversational AI, this comprehensive guide will equip you with the necessary knowledge to build a state-of-the-art RAG chatbot that elevates the user experience.
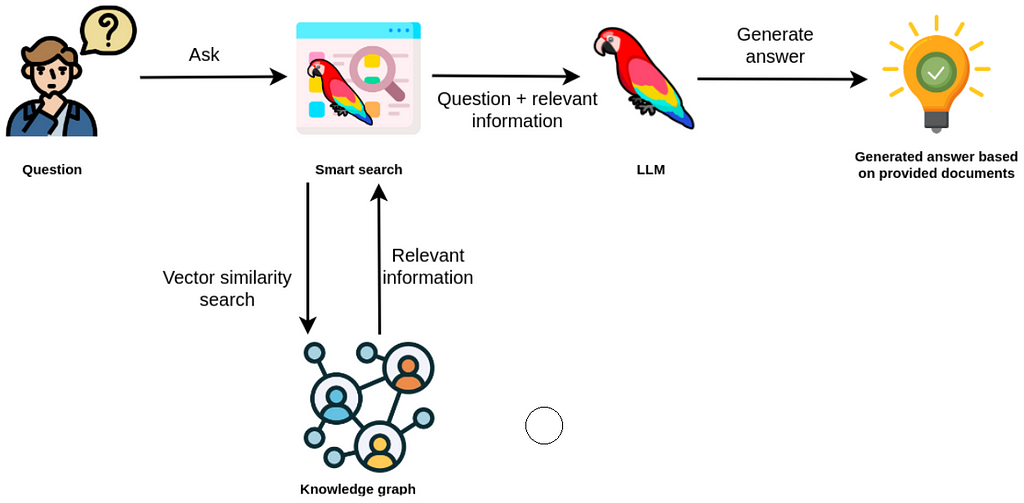
Vector similarity search in an RAG application. Image by source.
Building Blocks for Your RAG Chatbot
To construct a robust RAG (Retrieval-Augmented Generation) chatbot, you'll need to leverage several key technologies and frameworks. Here's an overview of the essential building blocks:
Neo4j: Graph Database for Knowledge Storage
Neo4j serves as the foundation for storing the knowledge base essential for the RAG chatbot. As a graph database, Neo4j excels in representing complex relationships between entities, making it ideal for organizing and querying structured data. Entities such as users, products, or concepts are represented as nodes, while relationships between them are depicted as edges, enabling efficient retrieval and traversal of interconnected information.
Langchain: The NLP Engine for Your RAG Chatbot
Langchain plays a critical role in building a RAG chatbot. It functions as the NLP (Natural Language Processing) engine, analyzing user queries to extract key entities and their relationships. This processed information acts as a bridge between natural language and the structured knowledge stored within Neo4j. By efficiently retrieving relevant data based on Langchain's analysis, the chatbot, powered by OpenAI's language generation capabilities, can deliver accurate and context-aware responses.
OpenAI: Provider of Large Language Models (LLMs)
OpenAI offers state-of-the-art large language models (LLMs) such as GPT-3 and GPT-4, which serve as the generative component of the RAG chatbot. These LLMs possess advanced natural language understanding and generation capabilities, enabling them to generate coherent and contextually relevant responses based on the input provided by the user. Integrating OpenAI's LLMs into the RAG chatbot enhances its ability to engage in meaningful conversations and provide insightful information.
Installation
To get started with building your RAG chatbot, you'll need to set up a Python environment and install the required libraries. Follow these steps:
Create a Virtual Environment
It's a good practice to create a virtual environment to keep your project dependencies isolated. You can use venv or conda to create a virtual environment.
python -m venv myenv
source myenv/bin/activate # On Windows, use `myenv\Scripts\activate`
# For conda
conda create -n myenv python=3.9
conda activate myenv
Install Required Libraries
%pip install --upgrade --quiet neo4j
%pip install --upgrade --quiet langchain-openai
%pip install --upgrade --quiet tiktoken
This will install neo4j for interacting with the Neo4j database, langchain-openai for integrating with OpenAI's language models, and tiktoken for efficient text tokenization.
Set Up Environment Variables
Create a .env file in your project directory and add your OpenAI API key and Neo4j credentials:
OPENAI_API_KEY = your_openai_api_key
NEO4J_URL = your_neo4j_url
NEO4J_USERNAME = your_neo4j_username
NEO4J_PASSWORD = your_neo4j_password
Replace the placeholders with your actual API key and Neo4j credentials.
Read Environment Variables
In your Python script, import the os module and the load_dotenv function from the dotenv library to read the environment variables:
import os
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.environ.get("OPENAI_API_KEY")
neo4j_url = os.environ.get("NEO4J_URL")
neo4j_username = os.environ.get("NEO4J_USERNAME")
neo4j_password = os.environ.get("NEO4J_PASSWORD")
This code will load the environment variables from the .env file, allowing you to access them securely in your Python script.
With your environment set up and the required libraries installed, you're ready to start building your RAG chatbot using Neo4j, Langchain, and OpenAI.
Comparing Neo4j and ChromaDB for Information Retrieval in RAG Chatbots
When choosing a knowledge store for a RAG chatbot, the decision often narrows down to traditional vector stores like ChromaDB and graph databases like Neo4j. Both have their strengths, but Neo4j offers distinct advantages for complex knowledge retrieval due to its ability to model intricate relationships and support query validation. Here's a look at why Neo4j might be the better choice, illustrated with code snippets and outputs from a query about Napoleon Bonaparte.
For a deeper understanding and practical examples of using ChromaDB in similar contexts, you can refer to these insightful resources:
Neo4j
Neo4j is a graph database that specializes in handling complex relationships and structured data. It's designed for scenarios that require entity-based queries, detailed context, and flexible data retrieval. With Neo4j, you can represent entities as nodes and their connections as edges, allowing you to create and traverse knowledge graphs efficiently.
Here's an example of querying a RAG application using Neo4j to retrieve information about Napoleon Bonaparte:
from langchain.chains import GraphCypherQAChain
from langchain.chat_models import ChatOpenAI
# Set up the GraphCypherQAChain
cypher_chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
validate_cypher=True,
verbose=True
)
# Run the query
response = cypher_chain.run("Who was Napoleon Bonaparte")
# Output from the query
# Generated Cypher:
# MATCH (p:Person {name: "Napoleon Bonaparte"}) RETURN p;
# Full Context:
# [{'p': {'birthdate': '15 August 1769', 'occupation': 'emperor, military commander',
# 'nationality': 'French', 'regnalname': 'Napoleon I', 'name': 'Napoleon Bonaparte',
# 'birthname': 'Napoleone di Buonaparte', 'id': 'Napoleon Bonaparte', 'deathdate': '5 May 1821'}}]
# > Finished chain.
This output demonstrates Neo4j's ability to retrieve structured and contextualized data, complete with entity details and their relationships. Neo4j is ideal for complex relationships and graph-based structures.
ChromaDB
ChromaDB, on the other hand, is a vector store optimized for similarity searches. It uses embeddings to represent text and is efficient for retrieving unstructured information. ChromaDB is suitable for applications where quick text-based retrieval is required without complex relationships.
An example query with ChromaDB might look like this:
# Similarity search in ChromaDB
docs = db.similarity_search("Who was Napoleon Bonaparte")
# Print the result
print(docs[0])
# Output from the query
# page_content="Napoleon had a lasting impact on the world, bringing modernizing reforms to France and Western Europe[...]
# However, his mixed record on civil rights and exploitation of conquered territories adversely affect his reputation."
# metadata={'source': 'data/sample_data.txt'}
ChromaDB retrieves relevant text based on similarity, but it doesn't provide the detailed context and complex relationships found in Neo4j.
Which to Choose?
Choosing between Neo4j and ChromaDB depends on your specific needs:
If your application involves structured data with complex relationships, Neo4j is the better choice.
If you need quick text-based retrieval without intricate relationships, ChromaDB might be more efficient.
Here's an example of a knowledge graph in Neo4j that illustrates how entities are connected:
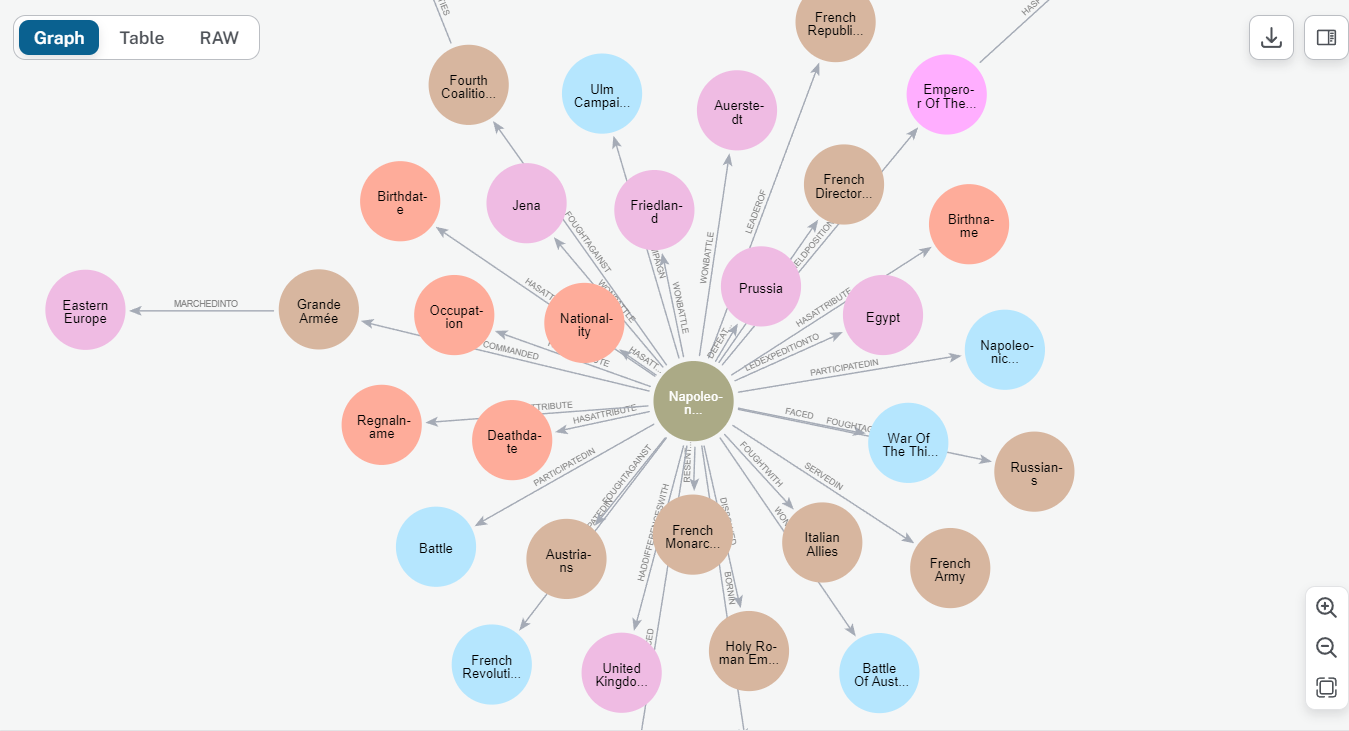
Knowledge graph generated from Napoleon's data. Image by author.
This graph visualization shows how Neo4j organizes data with nodes and relationships, offering efficient retrieval and context for RAG chatbots.
By considering the strengths and use cases of Neo4j and ChromaDB, you can make an informed decision about which technology is best for your RAG chatbot.
Creating a vector store in Neo4j
After deciding to use Neo4j for your RAG (Retrieval-Augmented Generation) chatbot, the next step is to set up the vector store in Neo4j. This section provides the essential steps to create a vector store, explaining how to integrate Langchain, OpenAI embeddings, and Neo4j to enable efficient similarity searches.
Langchain offers a seamless integration with Neo4j, allowing you to create a vector store directly within the graph database. This approach lets you store text documents and their corresponding embeddings for quick retrieval, enabling your chatbot to deliver relevant responses.
Here's a function that demonstrates how to create a vector store in Neo4j using Langchain:
from langchain.docstore.document import Document
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
def create_vector_store(file_path, neo4j_url, neo4j_username, neo4j_password):
# Load documents
loader = TextLoader(file_path)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=10)
docs = text_splitter.split_documents(documents)
# Initialize embeddings
embeddings = OpenAIEmbeddings()
# Create vector store in Neo4j
db = Neo4jVector.from_documents(
docs, embeddings, url=neo4j_url, username=neo4j_username, password=neo4j_password
)
return db
You can call this function with the appropriate file path and Neo4j credentials (read from the environment variables) to create the vector store.
file_path = "/path/to/your/text/file.txt"
db = create_vector_store(file_path, neo4j_url, neo4j_username, neo4j_password)
With the vector store set up, you can perform similarity searches by providing a query text:
query = "Your query text"
docs_with_score = db.similarity_search_with_score(query, k=4)
This code will retrieve the most relevant documents based on the cosine similarity between the query embedding and the document embeddings stored in the vector store.
Loading additional documents
You can use the add_documents method to load additional documents into an instantiated vector index.
db.add_documents(
[
Document(
page_content="LangChain is the coolest library since the Library of Alexandria",
metadata={"author": "Tomaz", "confidence": 1.0}
)
],
ids=["langchain"],
)
LangChain allows you to provide document ids to the add_document method, which can be used to sync information across different system and make it easier to update or delete relevant text chunks.
Querying an existing Vector Store
In some cases, you may already have a vector store set up and populated with documents and their embeddings. Langchain provides a convenient way to initialize and query an existing vector store in Neo4j.
# Initialize an existing vector store
index_name = "vector" # default index name
store = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
url=neo4j_url,
username=neo4j_username,
password=neo4j_password,
index_name=index_name,
)
# Perform similarity search
query = "Tell me about dorothy's story in brief."
docs_with_score = store.similarity_search_with_score(query, k=4)
Rag-based chatbot using Neo4j
Now that we have our vector store set up in Neo4j and can perform similarity searches, let's take it a step further and build a retrieval-augmented generation (RAG) chatbot using Langchain and OpenAI's language model.
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import ChatOpenAI
retriever = store.as_retriever()
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0), chain_type="stuff", retriever=retriever
)
output = chain(
{"question": "Tell me about dorothy's story in brief."},
return_only_outputs=True,
)
# Dorothy and her friends went on a journey to the Emerald City to seek help from the Wizard of Oz. Along the way, they encountered various challenges and met different characters who joined them on their quest. Ultimately, Dorothy was able to return home to Kansas with the help of the Wizard.
The RetrievalQAWithSourcesChain leverages the vector store in Neo4j to retrieve relevant documents based on the user's query. It then passes these retrieved documents, along with the query, to the language model (in this case, ChatOpenAI). The language model generates a coherent and contextual response by incorporating the retrieved information and its own language-understanding capabilities.
This approach allows the chatbot to provide more accurate and informative responses by combining the power of retrieval from the structured knowledge base in Neo4j with the natural language generation capabilities of OpenAI's language models.
Enhancing RAG Chatbots with Vector Similarity Search
Building a Robust Foundation: Setting up a Neo4j Database
To begin our journey towards enhancing RAG (Retrieval-Augmented Generation) chatbots with advanced vector similarity search capabilities, it's imperative to establish a solid foundation. We commence by configuring a Neo4j database, a versatile graph database management system that aptly suits our requirements for efficient data representation and retrieval.
from langchain.graphs import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username ="neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)
Creating a Dynamic Vector Store
Central to our approach is the construction of a vector store, an organized repository of entities and their relationships within the system. This store serves as the backbone for our chatbot's knowledge base, facilitating efficient retrieval and contextual understanding.
import requests
url = "https://gist.githubusercontent.com/tomasonjo/08dc8ba0e19d592c4c3cde40dd6abcc3/raw/da8882249af3e819a80debf3160ebbb3513ee962/microservices.json"
import_query = requests.get(url).json()['query']
graph.query(
import_query
)
If you inspect the graph in the Neo4j Browser, you should get a similar visualization.
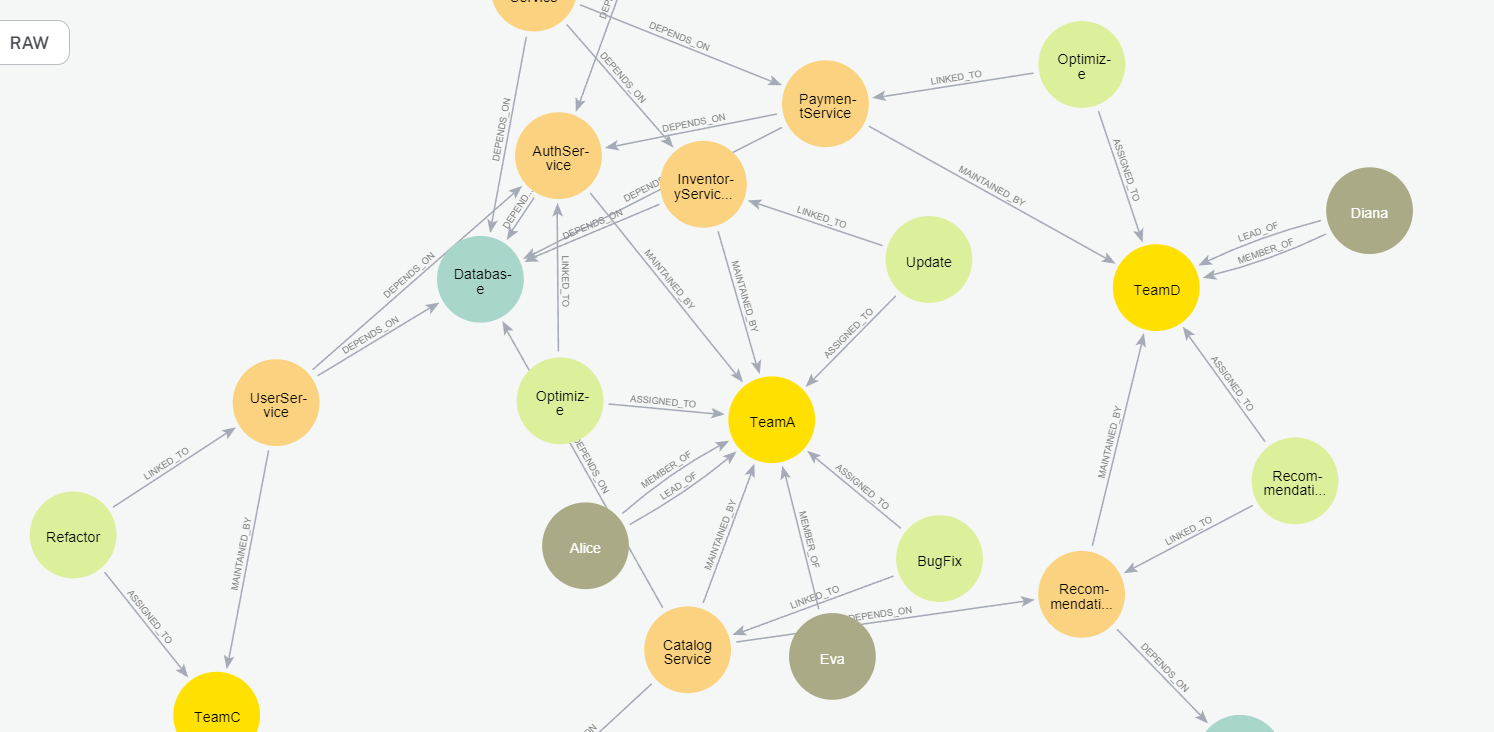
Subset of the DevOps graph. Image by author.
Orange nodes describe microservices. These microservices may have dependencies on one another, implying that the functioning or the outcome of one might be reliant on another’s operation. On the other hand, the green nodes represent tasks that are directly linked to these microservices. Besides showing how things are set up and their linked tasks, our graph also shows which teams are in charge of what.
Leveraging Vector Similarity Search: Empowering Contextual Retrieval
One of the key components of a Retrieval-Augmented Generation (RAG) chatbot is the ability to efficiently retrieve relevant information from a knowledge base to provide accurate and contextual responses. In this section, we'll explore how to leverage vector similarity search, a powerful technique that calculates text embeddings for each piece of information and retrieves the most similar items based on a user's query.
Setting Up a Vector Index in Neo4j
Let's assume that your domain knowledge is already stored in a Neo4j graph database as nodes and relationships. To enable vector similarity search, we need to calculate the embedding values for each node based on its relevant properties (e.g., name, description, status) and create a vector index. This can be achieved using the from_existing_graph method provided by Langchain:
import os
from langchain.vectorstores.neo4j_vector import Neo4jVector
from langchain.embeddings.openai import OpenAIEmbeddings
os.environ['OPENAI_API_KEY'] = "your_openai_api_key"
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
url=neo4j_url,
username=neo4j_username,
password=neo4j_password,
index_name='tasks',
node_label="Task",
text_node_properties=['name', 'description', 'status'],
embedding_node_property='embedding',
)
In this example, we're using the from_existing_graph method to create a vector index called 'tasks' based on the 'Task' nodes in our Neo4j graph. The embeddings are calculated using the OpenAIEmbeddings model, and they're stored in the 'embedding' property of each 'Task' node.
Performing Vector Similarity Search
With the vector index set up, we can now perform similarity searches to retrieve relevant information based on a user's query:
response = vector_index.similarity_search(
"How will RecommendationService be updated?"
)
print(response[0].page_content)
# name: BugFix
# description: Add a new feature to RecommendationService to provide ...
# status: In Progress
The similarity_search method returns the most relevant nodes based on the cosine similarity between the query embedding and the node embeddings stored in the vector index.
Integrating with a RAG Chatbot
To incorporate the vector similarity search into our RAG chatbot, we can wrap the vector index into a RetrievalQA module from Langchain:
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
vector_qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=vector_index.as_retriever()
)
vector_qa.run(
"How will recommendation service be updated?"
)
# The RecommendationService is currently being updated to include a new feature
# that will provide more personalized and accurate product recommendations to
# users. This update involves leveraging user behavior and preference data to
# enhance the recommendation algorithm. The status of this update is currently
# in progress.
The RetrievalQA module takes the language model (in this case, ChatOpenAI) and the vector index as a retriever. When a user query is provided, it retrieves the relevant information from the vector index and passes it to the language model, which generates a coherent and contextual response.
Limitations and Enhancements
While vector similarity search is excellent for retrieving relevant information from unstructured text, it lacks the capability to analyze and aggregate structured information. In such cases, we can leverage Neo4j's Cypher query language to perform complex queries and aggregations on the graph data.
graph.query(
"MATCH (t:Task {status:'Open'}) RETURN count(*)"
)
# [{'count(*)': 5}]
By combining the power of vector similarity search for unstructured text retrieval and Cypher queries for structured data analysis, we can enhance the capabilities of our RAG chatbot, providing more accurate and comprehensive responses to user queries.
Conclusion
In this blog post, we've explored how to build a powerful RAG chatbot by leveraging the strengths of various technologies: Neo4j for storing and managing the knowledge graph, Langchain for constructing the NLP pipeline, and OpenAI's large language models for text generation. By combining these tools, you can create a chatbot that can understand complex queries, retrieve relevant information from a structured knowledge base, and generate coherent and contextual responses using state-of-the-art language models.
This approach not only enhances the chatbot's knowledge depth and accuracy but also enables greater flexibility and adaptability, as the knowledge base can be continuously updated or expanded to meet evolving requirements. For more practical insights and code examples related to ChromaDB and other technologies discussed, you can explore the following resources:
Blog: Using Langchain and open source vector DB Chroma for semantic search with OpenAI’s LLM
Code: GitHub repository for finding similar products using ChromaDB
Resources and Further Reading
For practical examples of leveraging vector databases and enhancing chatbot capabilities with Langchain and ChromaDB, consider exploring these additional resources:
Next Steps: Bringing AI into Your Business
Whether you're looking to integrate cutting-edge NLP models or deploy multimodal AI systems, we're here to support your journey. Reach out to us at contact@futuresmart.ai to learn more about how we can help.
Don't forget to check out our futuresmart.ai/case-studies to see how we've successfully partnered with companies to implement transformative AI solutions.
Let us help you take the next step in your AI journey.



