Leveraging ChromaDB for Finding Similar Products
Introduction
In today's dynamic e-commerce and retail landscape, the ability to efficiently find similar products is paramount for businesses looking to enhance customer experience and drive sales. Leveraging advanced technologies such as ChromaDB(VectorDB), offers a powerful solution to this challenge.
ChromaDB is an open-source vector database designed to efficiently store and retrieve vector embeddings. In the context of e-commerce, it plays a crucial role in obtaining accurate similar products by embedding product descriptions.
we'll explore how ChromaDB empowers e-commerce and retail industries to improve product discovery through its robust capabilities. And demonstrate how it can be leveraged to find similar products effectively, ultimately enhancing the overall shopping experience for consumers.
Fundamentals of ChromaDB
ChromaDB is to develop and build large language model applications. The database makes it simpler to store knowledge, skills, and facts for LLM applications.
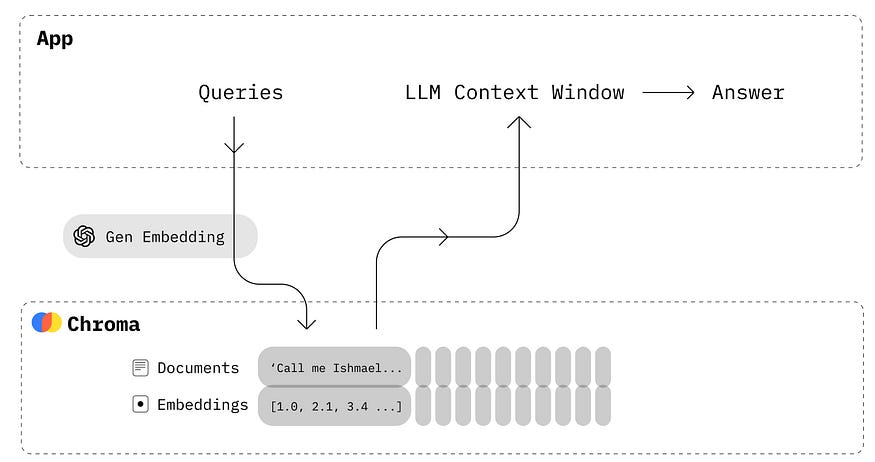
The above Diagram shows the workings of chromaDB when integrated with any LLM application. ChromaDB gives us a tool to perform the following functions:
Store embeddings and their metadata with ids.
Embed documents and queries
Search embeddings
ChromaDB is super simple to use and set up with any LLM-powered application. It is designed to boost developer productivity, making it a developer-friendly tool.
Installation
Installing the required packages.
!pip install chromadb -q
!pip install sentence-transformers -q
Creating ChromaDB Collection
We will import necessary modules to retrieve similar products from ChromaDB
import os
import csv
import chromadb
We need to create a chromadb collection to store the vector embeddings
client = chromadb.Client()
product_collection = client.create_collection("product_collection")
Adding File Data to ChromaDB
For our demonstration, we will use a list of products stored in CSV files to populate a ChromaDB collection. And we will use the Sentence Transformers "all-MiniLM-L6-v2" model to create embeddings, next we load the model and create embeddings for our documents.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
csv_file_path = "/content/products.csv"
documents = []
metadatas = []
ids = []
with open(csv_file_path, 'r', encoding='utf-8-sig') as file:
csv_reader = csv.reader(file)
next(csv_reader)
for row in csv_reader:
metadata = {
'id': row[0],
'name': row[1],
'category': row[2],
'price': float(row[3]),
'quantity': int(row[4]),
'description': row[5]
}
documents.append(row[5])
metadatas.append(metadata)
ids.append(row[0])
Here are some records from our products.csv file, including columns for id, name, category, price, quantity, and description.

Then, we can add the documents, metadata, and ids to the "product_collection" collection
product_collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)
Querying for Similar Products from chromadb
After adding the data from the CSV file to the ChromaDB, we can query ChromaDB to retrieve similar products. Additionally, we are filtering the ChromaDB collection based on 'category' and 'price'.
For example :
Imagine we're searching for a "wireless mouse with RGB lighting and programmable buttons" within a price range of $100 to $500, belonging to the "Electronics" category.
The following code retrieves products closely matching our query from a ChromaDB collection. Once the similar products are retrieved, the code will print them.
/co
# Define the text input you want to use as a query
query = "wireless mouse with RGB lighting and programmable buttons"
# Perform the query with the text input
query_results = product_collection.query(
query_texts=[query],
n_results=5,
#using the 'where' condition for filtering based on category and price
where={
'$and': [
{'category': {'$eq': 'Electronics'}},
{'price': {'$gte': 100}},
{'price': {'$lte': 500}}
]
}
)
# Extract metadata from query results
metadata = query_results.get('metadatas', [])[0]
print(metadata)
Similar Products
These are the retrieved similar products from ChromaDB.
[
{
"category": "Electronics",
"description": "Gaming mouse with customizable RGB lighting and programmable buttons",
"id": "67",
"name": "Mouse",
"price": 299.99,
"quantity": 120
},
{
"category": "Electronics",
"description": "Premium wireless mouse with ergonomic design, customizable buttons, and smooth scrolling",
"id": "66",
"name": "Mouse",
"price": 199.99,
"quantity": 150
},
{
"category": "Electronics",
"description": "Wireless optical mouse with ergonomic design and adjustable DPI settings",
"id": "30",
"name": "Mouse",
"price": 129.99,
"quantity": 150
},
{
"category": "Electronics",
"description": "Bluetooth mouse with silent clicking and rechargeable battery",
"id": "68",
"name": "Mouse",
"price": 499.99,
"quantity": 100
},
{
"category": "Electronics",
"description": "10-inch tablet with Full HD display and quad-core processor",
"id": "21",
"name": "Tablet",
"price": 299.99,
"quantity": 90
}
]
Conclusion
By leveraging ChromaDB, e-commerce businesses can significantly improve the accuracy and relevance of their search functionality. The ability to efficiently retrieve similar products based on their embeddings enables users to discover items that closely match their preferences and interests. This enhanced search capability leads to increased user satisfaction and engagement, ultimately driving higher conversion rates and sales.
I hope this blog provides you with information on how to retrieve similar products from ChromaDB and how we can utilize this capability on e-commerce platforms to recommend similar products, thereby enhancing customer satisfaction
And not only this we have created several other blogs and tutorials on vector databases and semantic search that dive even deeper into these topics.
If you wish to delve deeper into the Chroma vector database and Semantic search, you can explore this video tutorial or blog:
https://blog.futuresmart.ai/chromadb-an-open-source-vector-embedding-database#heading-conclusion



