Harnessing OpenAI Embeddings for Advanced NLP: Text Similarity, Semantic Search, and Clustering
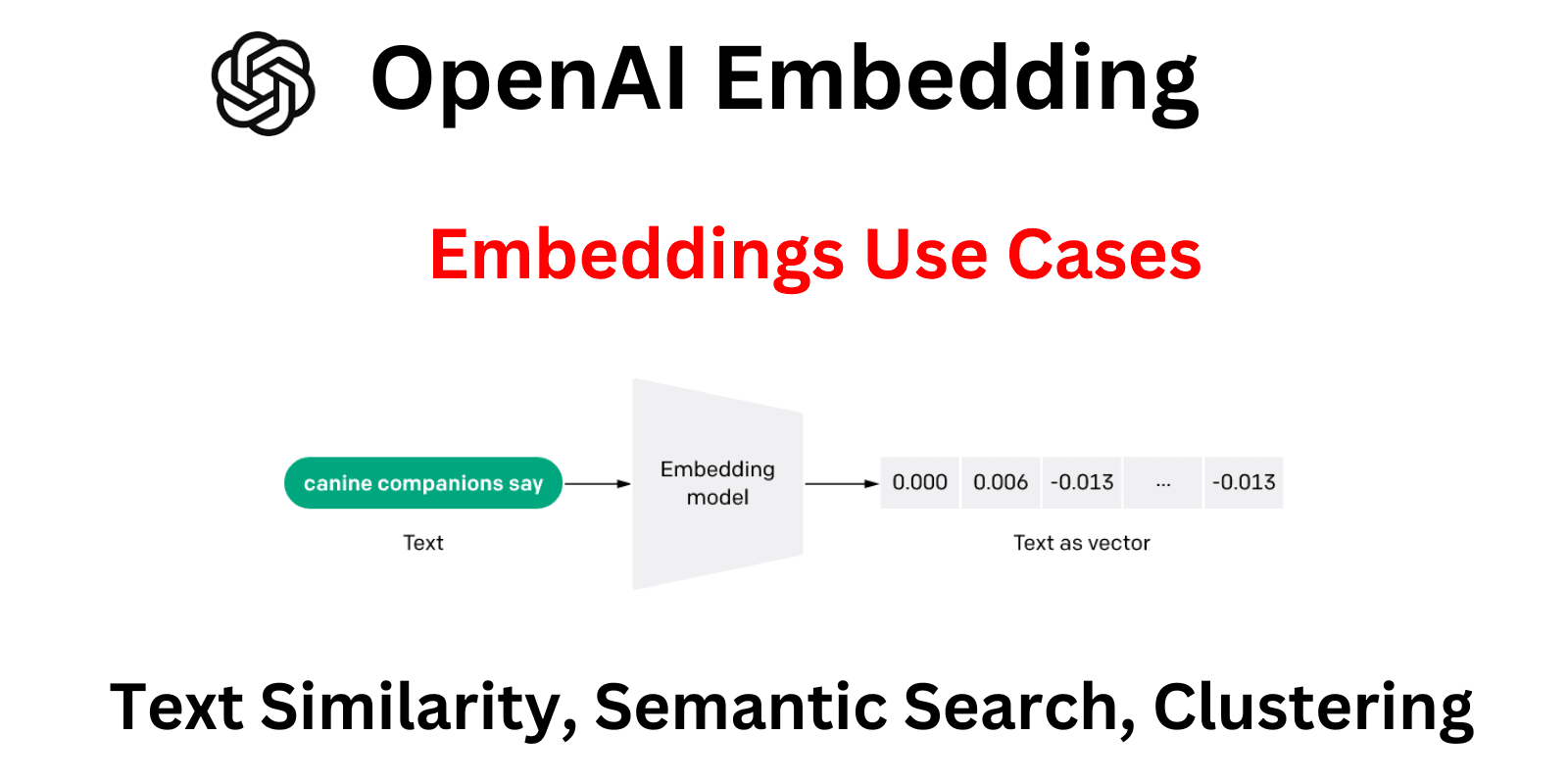
Introduction
OpenAI has made waves online with its innovative embedding and transcription models, leading to breakthroughs in NLP and speech recognition. These models enhance accuracy, efficiency, and flexibility while speeding up transcription services. In this blog, we will explore the potential of OpenAI Embeddings for advanced NLP tasks, and in our next blog, we will dive into OpenAI's Whisper transcription models. We'll cover the basics of word embeddings, their advantages, and how OpenAI Embeddings outperform older models. We'll also examine OpenAI Embeddings' applications, such as text similarity, semantic search, and clustering. Join us as we delve into the transformative power of OpenAI Embeddings in the realm of NLP.
What Are Word Embeddings?
One of the key challenges in NLP is representing language in a way that can be easily processed by machine learning algorithms. This is where embeddings come in.
An embedding is a way of representing words or phrases as vectors in a high-dimensional space. By mapping words to vectors, we can capture the meaning of words and their relationships with other words in a way that can be easily processed by machine learning algorithms.
Benefits Of Using Embeddings
The benefit of using embeddings is that they allow us to capture the meaning of words in a way that is more nuanced than simply counting the number of times a word appears in a document. For example, consider the words "cat" and "dog". These words may appear in similar contexts and therefore have similar embeddings because they are both types of pets. By contrast, the words "cat" and "computer" will likely have very different embeddings because they are not semantically related.
Why OpenAi Embeddings Model is Better Than Previous Embedding Models
OpenAI's new text-embedding model, text-embedding-ada-002, outperforms all previous embedding models on text search, code search, and sentence similarity while achieving equivalent performance on text classification. By unifying the capabilities of five different models, the /embeddings endpoint's interface has been greatly simplified. The new model also boasts a longer context length, and smaller embedding size, and is 90% cheaper than previous models of similar size, making it a more efficient and cost-effective choice for natural language processing tasks.
OpenAi Embeddings Use Cases
OpenAi embedding models and whisper gives us the power to create a diverse set of NLP apps by providing functionalities like text similarity, semantic search, clustering, etc.
Use Case 1: Text Similarity
OpenAi Similarity Embeddings models are good at capturing semantic similarity between two or more pieces of text.
Step1
!pip install openai
Install OpenAi Library
Step 2
import pandas as pd
import openai, numpy as np
from openai.embeddings_utils import get_embedding, cosine_similarity
Import the libraries
Step 3
api_key = 'Your API key here'
openai.api_key = api_key
Initialize your API key. You can get your own API key from - https://platform.openai.com/account/api-keys
Step 4
texts = ["eating food", "I am hungry", "I am traveling" , "exploring new places"]
resp = openai.Embedding.create(
input= texts,
engine="text-similarity-davinci-001")
embedding_a = resp['data'][0]['embedding']
embedding_b = resp['data'][1]['embedding']
embedding_c = resp['data'][2]['embedding']
embedding_d = resp['data'][3]['embedding']
li = []
for ele in resp['data']:
li.append(ele["embedding"])
## Finding text similarity percentages
for i in range(len(texts) - 1):
for j in range(i + 1, len(resp["data"])):
print("text similarity percentage between",texts[i], "and", texts[j],"is ", np.dot(resp['data'][i]['embedding'],resp['data'][j]['embedding'])*100)
Initialize the text-similarity-davinci-001 model. Then we provide a list of text as input to it. Then we store the embeddings of the sentences in their respective variables. Finally, we find the percentage similarity between the sentences by vector dot product using the NumPy module
Use Case 2: Semantic Search
Semantic Search is a technology that understands the context and meaning behind the words used in a search query, making it possible to deliver more relevant and accurate results. Semantic Search algorithms use natural language processing (NLP) and machine learning techniques to analyze the search query and match it with the most relevant content available on the web.
Follow Steps 1, 2, and 3 of Use Case 1
Step 4
datafile_path = "https://cdn.openai.com/API/examples/data/fine_food_reviews_with_embeddings_1k.csv" # for your convenience, we precomputed the embeddings
df = pd.read_csv(datafile_path)
df.head()
We loaded the data frame using the pandas module and saved it in the variable df. Now let us observe the data frame
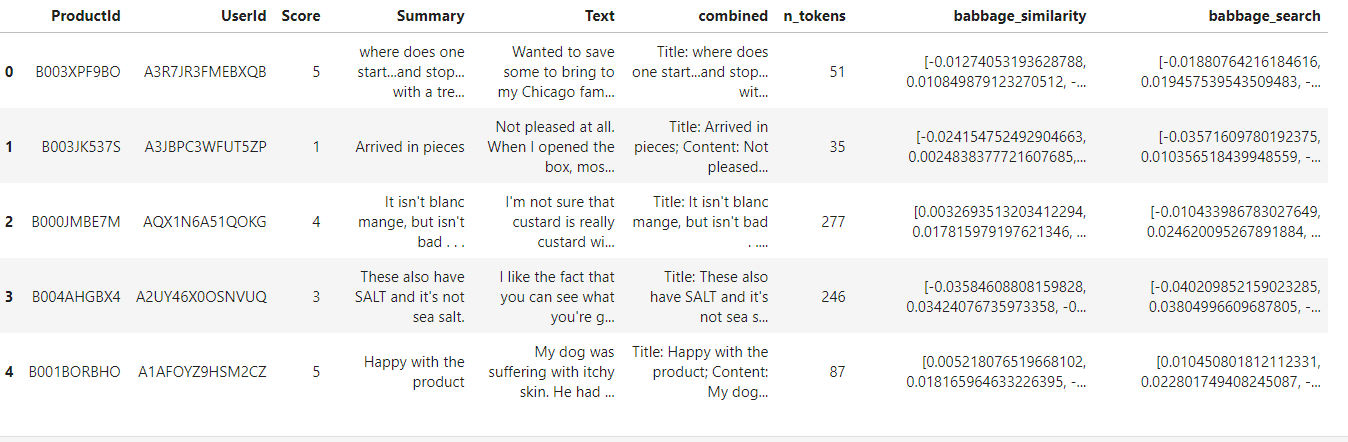
The data frame has 9 columns but our main focus will be on columns combined, babbage_similarity and babbage_search. The combined column is basically the concatenation of the Summary column which contains the title of the review and the Text column which contains the content of the review. babbage_similarity will be used when we are interested in finding the similarity between two sentences and babbage_search will be used when we are interested in searching a document.
Step 5
df["babbage_search"] = df.babbage_search.apply(eval).apply(np.array)
df["babbage_similarity"] = df.babbage_similarity.apply(eval).apply(np.array)
Convert the contents of columns - babbage_search and babbage_similarity from string to a NumPy ndarray.
Step 6
# search through the reviews for a specific product
def search_reviews(df, search_query, n=3):
embedding = get_embedding(
search_query,
engine="text-search-babbage-query-001"
)
df["similarities"] = df.babbage_search.apply(lambda x: cosine_similarity(x, embedding))
top_n = df.sort_values("similarities", ascending=False).head(n)
# res = top_n.combined.str.replace("Title: ", "").str.replace("; Content:", ": ")
return top_n
res = search_reviews(df, "delicious beans", n=3)
res['combined'].to_list()
We have created our custom search_reviews method which will take the user query and search it in the reviews and return the top 3 similar reviews based on the query provided. Our method takes three arguments- data frame, user query, and several reviews to be returned.
Next, we initialize the semantic search embedding model inside the method. Then we create a new column in our data frame called similarities where we store the similarity score between each review and the user query.
Next, we sort our data frame based on the similarities column in descending order and return the top 3 reviews with the highest similarity score.
Use Case 3: Clustering
The clustering process involves creating clusters, which are groups of documents that are more similar to each other than to documents in other clusters. These clusters can be used to identify themes, topics, or patterns within a dataset, and can be useful for various NLP applications, such as text classification, sentiment analysis, and recommendation systems.
Follow Steps 1, 2, and 3 of Use Case 1
Step 4
# source: https://stackoverflow.com/questions/55619176/how-to-cluster-similar-sentences-using-bert
from sklearn.cluster import KMeans
# Corpus with example sentences
corpus = ['A man is eating food.',
'A man is eating a piece of bread.',
'Horse is eating grass.',
'A man is eating pasta.',
'A Woman is eating Biryani.',
'The girl is carrying a baby.',
'The baby is carried by the woman',
'A man is riding a horse.',
'A man is riding a white horse on an enclosed ground.',
'A monkey is playing drums.',
'Someone in a gorilla costume is playing a set of drums.',
'A cheetah is running behind its prey.',
'A cheetah chases prey on across a field.',
'The cheetah is chasing a man who is riding the horse.',
'man and women with their baby are watching cheetah in zoo'
]
We import the KMeans clustering algorithm from sklearn module and then we create our own data corpus on which we will be performing clustering.
Step 5
response = openai.Embedding.create(
input=corpus,
model="text-similarity-babbage-001"
)
corpus_embeddings = [ d['embedding'] for d in response['data']]
# Normalize the embeddings to unit length
corpus_embeddings = corpus_embeddings / np.linalg.norm(corpus_embeddings, axis=1, keepdims=True)
In this step, we create embeddings for our data corpus using openai embedding model - "text-similarity-babbage-001".
Next, we create a list of corpus_embeddings where we store all the embeddings.
Finally, we Normalized the embeddings to unit length. We need to normalize the vectors in order to ensure that all dimensions are treated equally.
Step 6
clustering_model = KMeans(n_clusters=3)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
print(cluster_assignment)
clustered_sentences = {}
for sentence_id, cluster_id in enumerate(cluster_assignment):
if cluster_id not in clustered_sentences:
clustered_sentences[cluster_id] = []
clustered_sentences[cluster_id].append(corpus[sentence_id])
clustered_sentences
In the final step, we create an instance of KMeans and we pass n_clusters = 3 as we want to obtain three clusters. After this, we fit the model with the corpus of embeddings which we obtained in the previous step. Then we initialize a dictionary and pass cluster id as the key and clustered sentences as the value of the keys of the dictionary.
Sample Output

Conclusion
In this blog, we have learned about the powerful abilities of OpenAi and how we can leverage those abilities to build state-of-the-art applications. We started with embeddings and learned about its various use cases. In the next blog, we will make an app by leveraging the knowledge of this blog.
If you are more interested to learn about embeddings and their use cases, then be sure to check out the below YouTube tutorial.
To learn about more interesting and cool applications of LLMs look into our other Blogs and YouTube channel.
Also, want to learn about the state-of-the-art stuff in AI? Don't forget to subscribe to AI Demos. A place to learn about the latest and cutting-edge tools in AI!



