Integrating Llama 2 with Hugging Face and Langchain🦙

Search for a command to run...
This is wonderfull but very basic, if a source code is provided of its advanced version, would be much better
very informative and well structure
Graphiti is a compact yet powerful Python library that converts raw text or JSON into an AI Knowledge Graph—a structured store of facts that acts as AI Agent Memory. Below is the exact workflow I used to load FutureSmart AI data into Neo4j, explore t...
In this blog we’ll walk through practical steps to add long‑term memory to your AI agents using Mem0 and LangGraph. We’ll build incrementally, tackling one section at a time so you can follow along and run the code as you read. Table of Contents Mem...

Retrieval-Augmented Generation (RAG) is becoming the go-to pattern for building AI systems that can fetch real-time or domain-specific knowledge on demand. But RAG alone doesn’t make your chatbot smart. With LangGraph, you can build stateful, agent-l...

Introduction In the era of advanced AI applications, Retrieval-Augmented Generation (RAG) stands out as a game-changing approach. By combining retrieval techniques with generative models, RAG enhances the quality, accuracy, and relevance of generated...

Introduction Search engines and retrieval systems have evolved to become remarkably intelligent. They no longer rely on exact keyword matches or rigid rules to find what you're looking for. Instead, they understand the context and meaning behind your...

On July 18, 2023, Meta released LLaMA-2, a collection of pre-trained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. The pre-trained models exhibit notable advancements compared to the Llama 1 models. These enhancements encompass training on 40% more tokens, possessing a substantially extended context length (4k tokens 🤯), and employing grouped-query attention to facilitate rapid inference for the 70B model🔥!
Nevertheless, the most exhilarating aspect of this launch is the fine-tuned models (Llama 2-Chat), meticulously optimized for dialogue applications through the implementation of Reinforcement Learning from Human Feedback (RLHF). Spanning a diverse spectrum of helpfulness and safety benchmarks, the Llama 2-Chat models outperform a majority of open models and achieve performance on par with ChatGPT, as confirmed by human evaluations.
Now to use the LLama 2 models, one has to request access to the models via the Meta website and the meta-llama/Llama-2-7b-chat-hf model card on Hugging Face.
You will also need a Hugging Face Access token to use the Llama-2-7b-chat-hf model from Hugging Face.
Here's how you can use it!🤩
Open your Google Colab Notebook. Make sure that you switch your runtime type to any GPU runtime available(this speeds up the process!)
!pip install -q transformers accelerate langchain
!huggingface-cli login
transformers: Transformers provides APIs and tools to easily download and train state-of-the-art pretrained models for 📝 Natural Language Processing, 🖼️ Computer Vision, 🗣️ Audio, etc.
accelerate: Accelerate is a library that enables PyTorch code to be run across any distributed configuration by adding a few lines of code!
langchain: LangChain is a framework for developing applications powered by language models. It enables applications that are:
Data-aware: Connect a language model to other sources of data
Agentic: Allows a language model to interact with its environment
huggingface-cli login: The huggingface-cli tool provides several commands for interacting with the Hugging Face Hub from the command line. One of these commands is login, which allows users to authenticate themselves on the Hub using their credentials.
Computers don't understand text. So, we use tokenizers that convert text to numbers that computers can understand and interpret. Pipelines are objects that abstract complex code from the library and provide a simple API for use.
from transformers import AutoTokenizer
import transformers
import torch
import accelerate
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer=AutoTokenizer.from_pretrained(model)
pipeline=transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
trust_remote_code (bool, optional, defaults to False) — Whether or not to allow for custom code defined on the Hub in their modeling, configuration, tokenization or even pipeline files. This option should only be set to True for repositories you trust and in which you have read the code, as it will execute code present on the Hub on your local machine.
device_map (str or Dict[str, Union[int, str, torch.device], optional) — Sent directly as model_kwargs (just a simpler shortcut). When accelerate library is present, set device_map="auto" to compute the most optimized device_map automatically (see here for more information).
do_sample: if set to True, this parameter enables decoding strategies such as multinomial sampling, beam-search multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability distribution over the entire vocabulary with various strategy-specific adjustments.
top_k (int, optional, defaults to None) — The number of top labels that will be returned by the pipeline. If the provided number is None or higher than the number of labels available in the model configuration, it will default to the number of labels.
num_return_sequences: The number of sequence candidates to return for each input. This option is only available for the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding strategies like greedy search and contrastive search return a single output sequence.
sequences = pipeline(
'Hi! I like cooking. Can you suggest some recipes?\n')
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Output: Result: Hi! I like cooking. Can you suggest some recipes? I'm glad you're interested in cooking! There are so many delicious recipes out there, but I'll give you a few suggestions to get you started: 1. Chicken Parmesan: Breaded and fried chicken topped with marinara sauce and melted mozzarella cheese. Serve with pasta or a green salad...
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.chains import ConversationChain
import transformers
import torch
import warnings
warnings.filterwarnings('ignore')
model="meta-llama/Llama-2-7b-chat-hf"
tokenizer=AutoTokenizer.from_pretrained(model)
pipeline=transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm=HuggingFacePipeline(pipeline=pipeline, model_kwargs={'temperature':0.7})
One of the biggest advantages of open-access models is that one has full control over the system prompt in chat applications. The prompt template should be a template that was used during the model's training procedure. For Llama-2 chat, the template looks something like this:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]
We define our prompt template in the following way:
prompt_template = """<s>[INST] <<SYS>>
{{ You are a helpful AI Assistant}}<<SYS>>
###
Previous Conversation:
'''
{history}
'''
{{{input}}}[/INST]
"""
prompt = PromptTemplate(template=prompt_template, input_variables=['input', 'history'])
Chains are like entities that combine various features like prompts, memories and different LLMs to generate the desired output.
ConversasationChain of the LangChain Library is the Chain used to have human-assistant conversations and it loads context from the memory. Note: All the conversations are saved in the memory leading to a large buffer size unlike ConversationBufferWindowMemory that stores the last K interactions. To understand this even better, you might have a look at these blogs: Langchain Memory with LLMs for Advanced Conversational AI and Chatbots and Building an Interactive Chatbot with Langchain, ChatGPT, Pinecone, and Streamlit
chain = ConversationChain(llm=llm, prompt=prompt)
chain.run("What is the capital Of India?")
Output: "Hello! I'm happy to help you with your question. The capital of India is New Delhi. Did you have any other questions?"
To prevent our context buffer from becoming very large, we can use ConversationBufferWindowMemory. Just modify the part of the code where you have defined the chain. Then, run the chain again!
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=5)
chain = ConversationChain(
llm=llm,
prompt=prompt,
memory=memory
)
Voila! You can now converse with Llama-2. However, this is just the beginning. The potential applications of open-source Large Language Models are virtually limitless.
Need to use these models for specific use cases? Worry not! You can even fine-tune these models for your specific needs!
Still skeptical about the performance of the Llama-2 models?🤨
Here are some benchmarks:
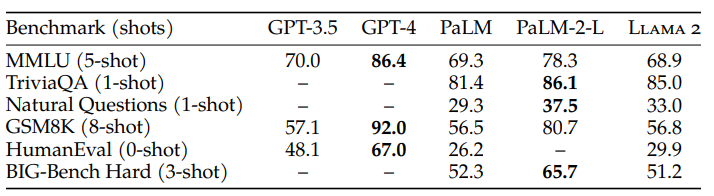
It is to be noted that although in MMLU and GSM8K benchmarks Llama 2 hits nearly the same scores as GPT-3.5😎, in a HumanEval (coding) benchmark, it ranks way behind it (29,9% vs. 48,1%) — not no mention GPT-4, which outperforms Llama 2 more than twice (67%).😩
In conclusion, the rapid advancement of artificial intelligence has brought us to a pivotal juncture in our understanding of intelligence. The conventional notion that "Humans are the most intelligent creatures" is undergoing a profound transformation as AI systems demonstrate remarkable capabilities across an array of tasks. While AI technologies are not sentient beings like humans, their ability to process vast amounts of data, learn from patterns, and make complex decisions challenges the traditional boundaries of intelligence. As AI continues to evolve, it blurs the distinction between human and machine intelligence, inviting us to question and reevaluate our understanding of what it truly means to be intelligent. Rather than replacing human intelligence, AI is expanding the horizons of human potential and reshaping the narrative of intelligence itself. This journey into the age of AI compels us to explore not only the remarkable feats of machines but also the unique qualities that make us inherently human.
The sky is not the limit; perhaps the moon is 🌒!
Still, considering GPT models? Check these out:
Follow FutureSmart AI to stay up-to-date with the latest and most fascinating AI-related blogs - FutureSmart AI
Looking to catch up on the latest AI tools and applications? Look no further than AI Demos This directory features a wide range of video demonstrations showcasing the latest and most innovative AI technologies. Whether you're an AI enthusiast, researcher, or simply curious about the possibilities of this exciting field, AI Demos is your go-to resource for education and inspiration. Explore the future of AI today with aidemos.com