Mastering Hugging Face Inference API: Integrating NLP Models for Real-Time Predictions

Inference API is a type of API that allows users to make predictions using pre-trained machine-learning models. It is a crucial component in the deployment of machine learning models for real-time predictions and decision-making. By using an Inference API, developers can integrate pre-trained machine learning models into their applications, enabling them to make predictions based on new data in real-time.
In today's world, natural language processing (NLP) models are increasingly being used in various applications such as chatbots, voice assistants, and sentiment analysis. These models can process large volumes of text data and extract insights that can be used for decision-making. However, to use these models effectively, they need to be integrated into applications in a way that allows them to be used for real-time predictions. This is where Inference API comes in, making it possible for developers to integrate NLP models into their applications and enable them to provide real-time predictions.
Hugging Face Inference API
![]()
Hugging Face is a popular natural language processing (NLP) company that provides a wide range of NLP tools and resources for developers, researchers, and businesses. One of their most popular offerings is the Hugging Face API, which provides access to pre-trained NLP models for a variety of tasks such as text classification, sentiment analysis, question answering, and more. The API allows developers to easily integrate these pre-trained models into their applications, without the need for extensive training or model development. The Hugging Face API is widely used in the NLP community and has helped to democratize access to advanced NLP capabilities, making it easier for more people to build sophisticated natural language applications.
Types of NLP Models for Inference
Several types of NLP models can be used for inference, each with its own strengths and use cases. Some of the most common types of NLP models for inference include:
Text Classification Models: These models are used to classify text into pre-defined categories such as spam/not spam, positive/negative sentiment, or topic classification.
Named Entity Recognition (NER) Models: These models are used to identify and extract entities such as names, organizations, and locations from the text.
Sentiment Analysis Models: These models are used to determine the emotional tone of a piece of text, such as whether a tweet is positive, negative, or neutral.
Language Translation Models: These models are used to translate text from one language to another, which can be useful for applications that require multilingual support.
Question Answering Models: These models are used to answer questions based on a given context or passage, such as answering questions on a reading comprehension test.
Text Summarization Models: These models are used to summarize long pieces of text into shorter, more concise summaries, which can be useful for applications such as news aggregation or document summarization.
By using these types of NLP models for inference, developers can extract useful insights from text data and use them for real-time predictions and decision-making.
How to use Hugging Face Inference API?
First, create a Hugging Face account and select the pre-trained NLP model you want to use. For this example, let's use the pre-trained BERT model for text classification.
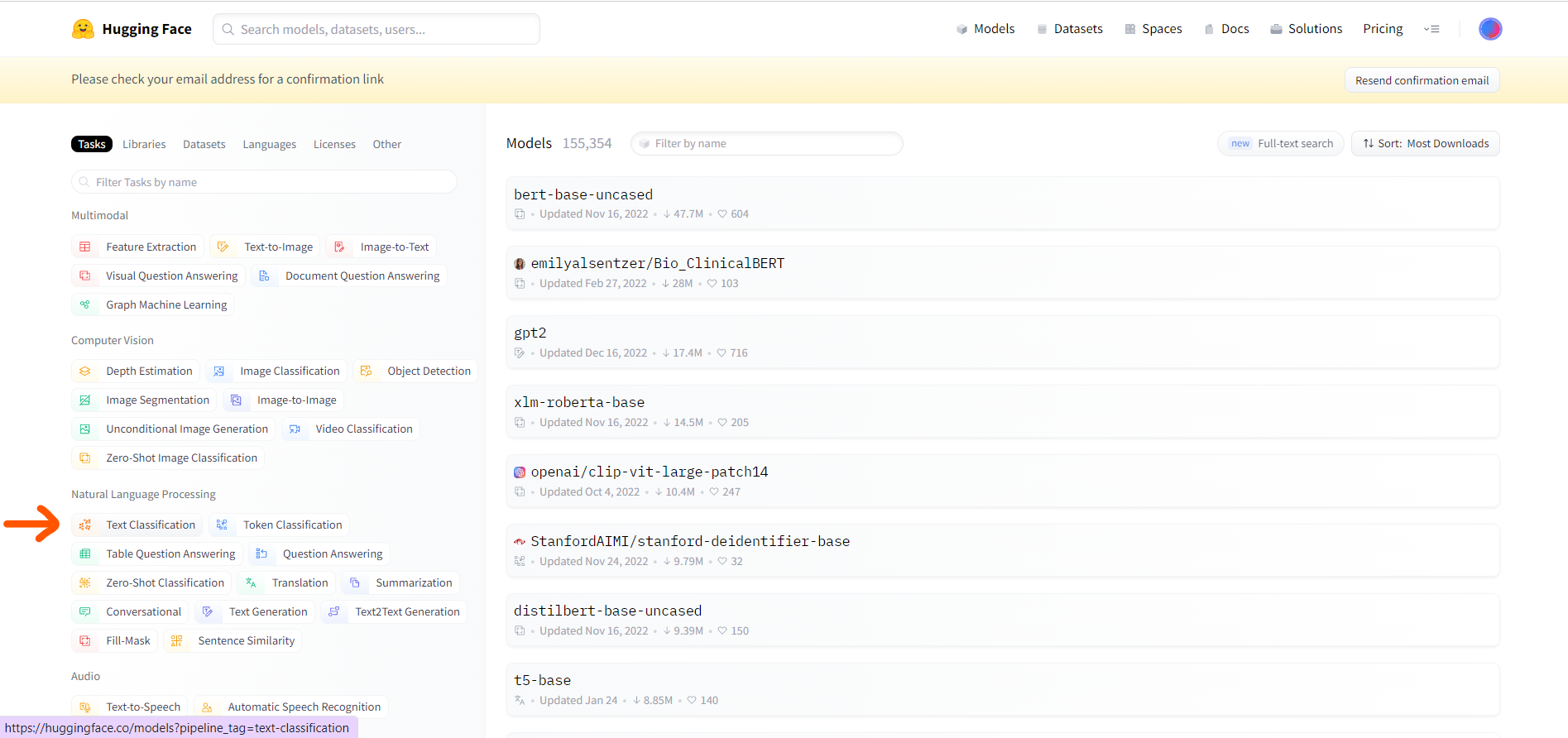
Search BERT in the search bar.
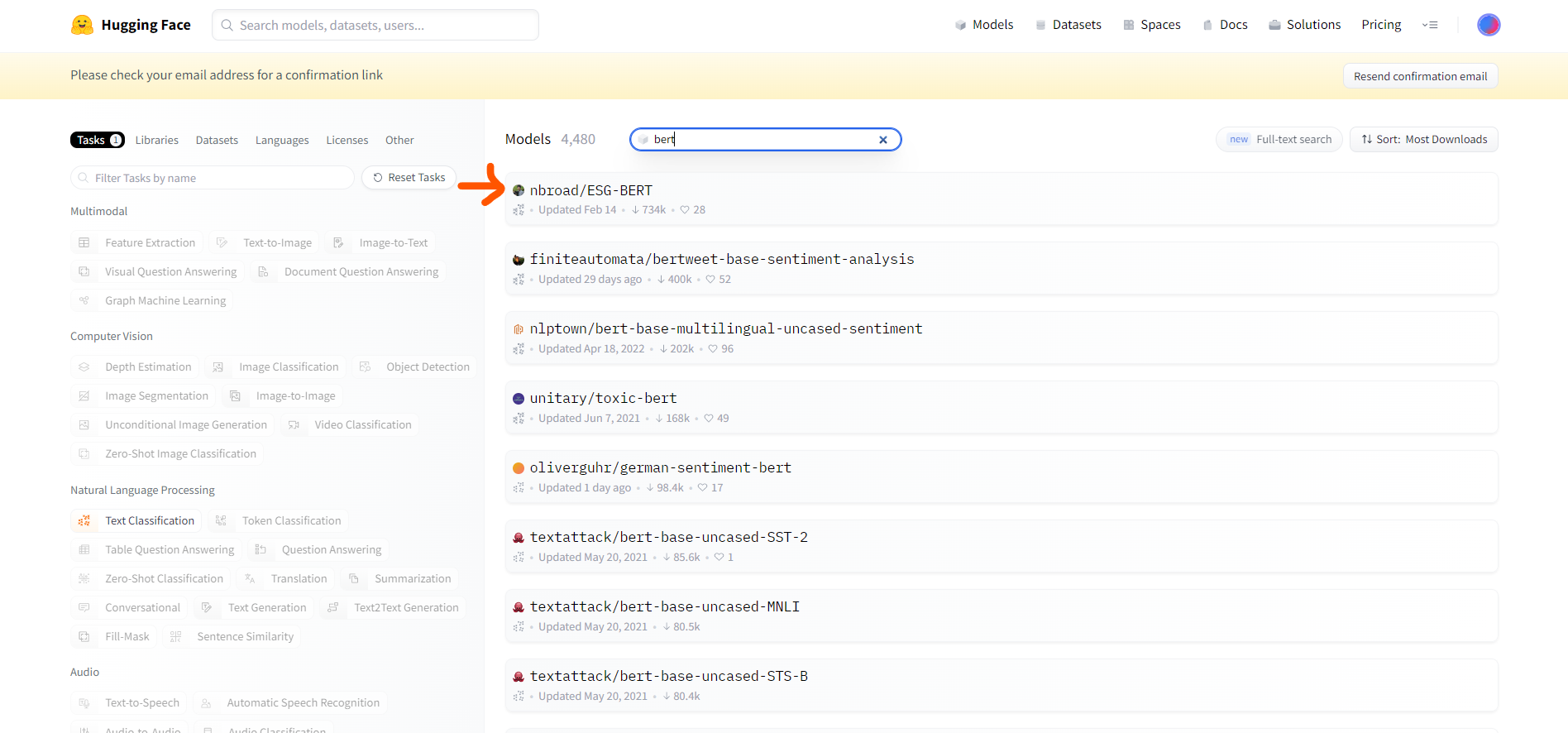
Next, go to the Hugging Face API documentation for the BERT model.
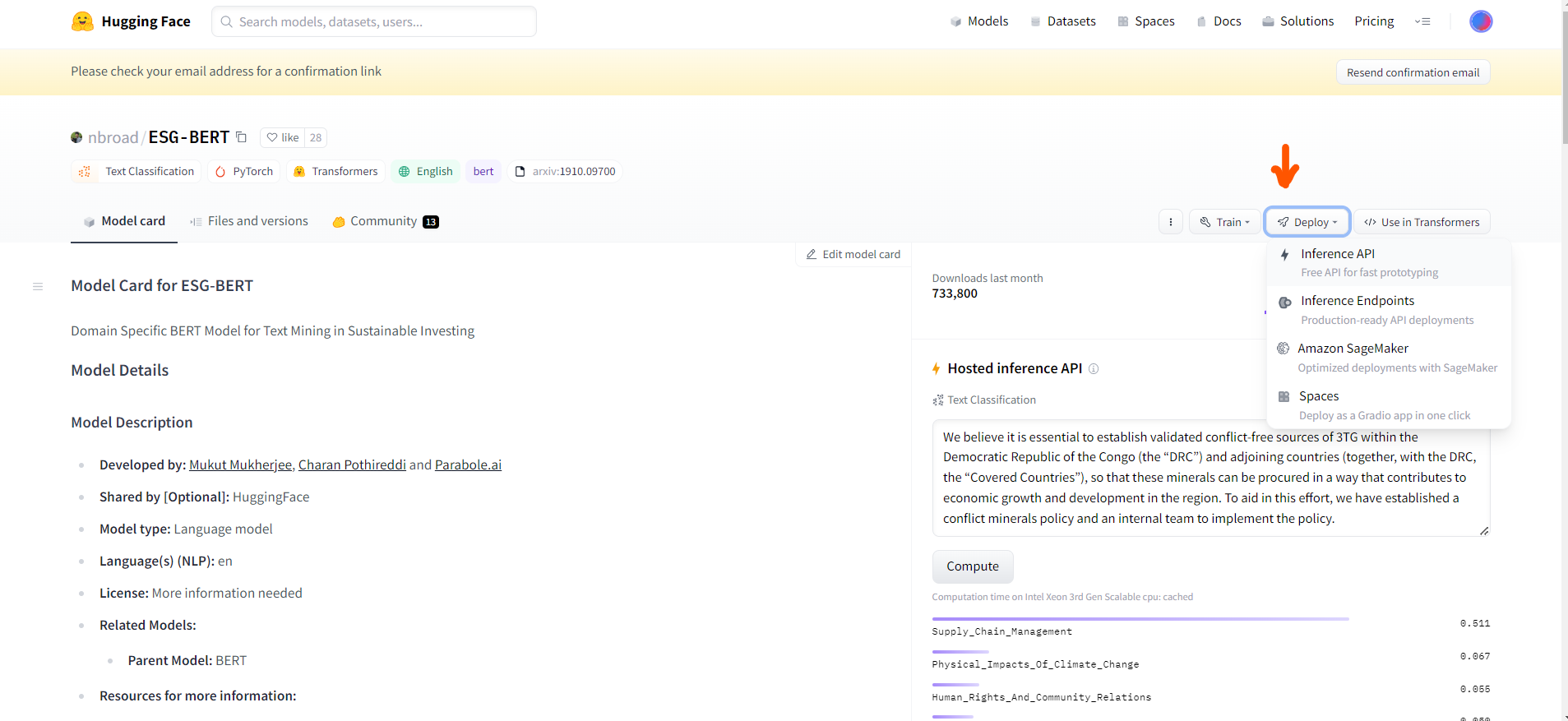
Find the endpoint URL for the model. This will be the URL you use to make API requests to the model.
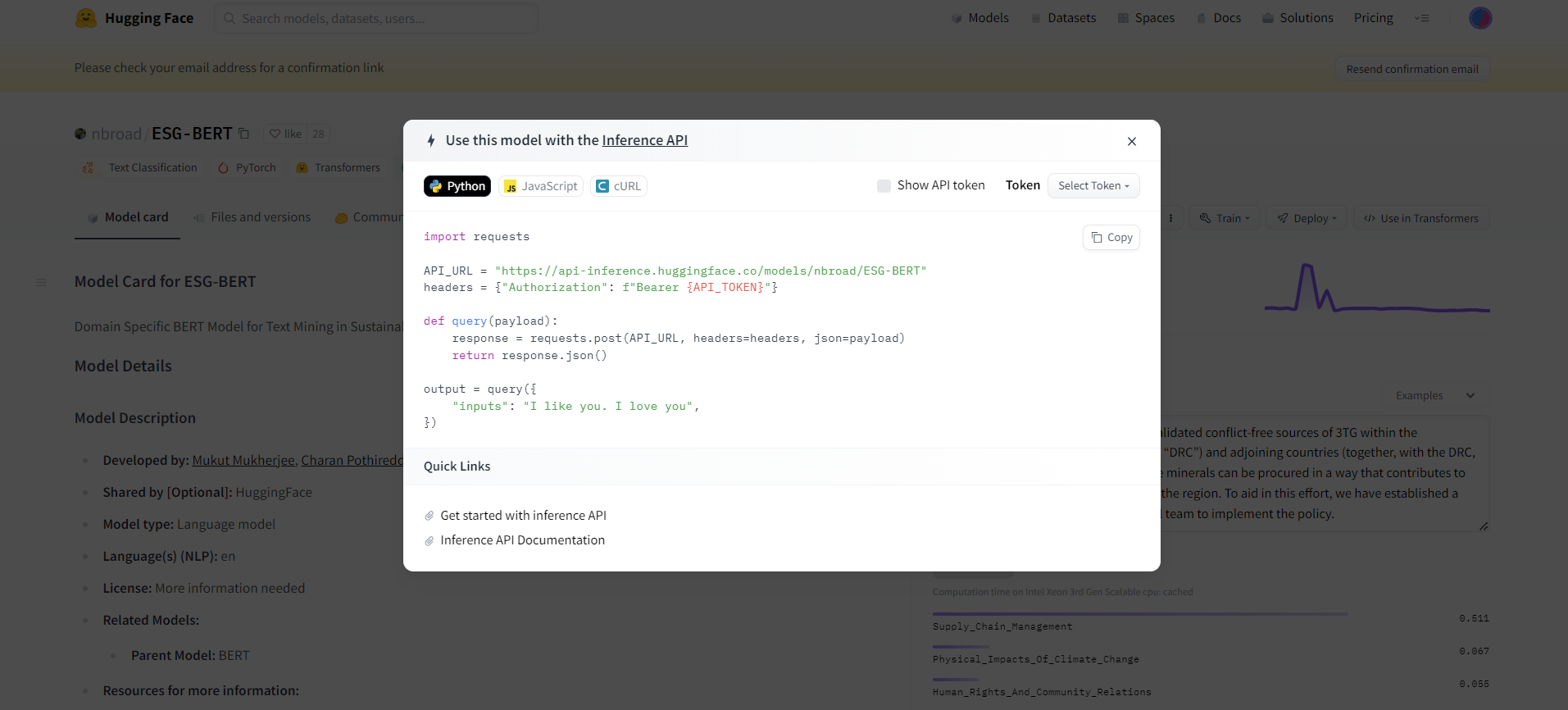
api_url = "https://api-inference.huggingface.co/models/nbroad/ESG-BERT"Click on the "Select Token" button in the "Use this model with the Inference API" dialogue box. Enter a name for your API token and click on the "Create" button to generate the token.
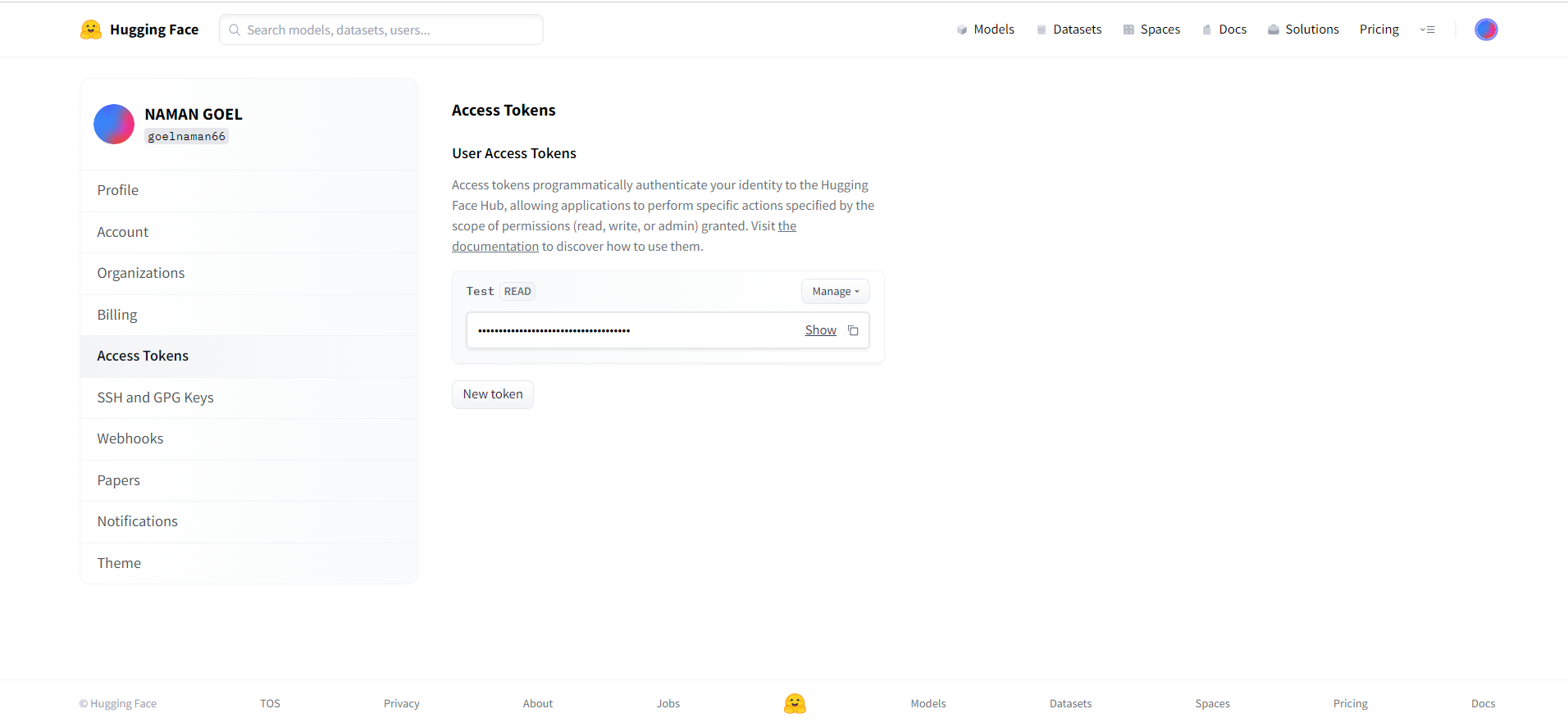
After creating the token, you'll be taken to a page with the token details, including the token value itself. Copy the token value and save it somewhere secure, as you'll need it to make API requests to the selected model.
Open up a code editor or Jupyter Notebook and import the
requestslibrary, which we'll use to make API requests to the model.import requestsWith the
requestslibrary imported, we can now create an API request to the BERT model. To do this, we'll need to specify the endpoint URL for the model, our API key, and the input text we want to classify.api_key = "YOUR_API_KEY_HERE" headers = {"Authorization": f"Bearer {api_key}"} data = {"inputs": "This is a positive example."} response = requests.post(api_url, headers=headers, json=data)In the code above, we've created an API request to the BERT model with the input text "This is a positive example." We've also specified our API key and endpoint URL in the headers of the request.
After sending the API request, we'll get a response back from the model with its predictions. We can extract the predictions from the response using the following code:
predictions = response.json()[0]["score"]In the code above, we've extracted the prediction scores for each class from the API response. In this case, since we're using a binary text classification model, there are two prediction scores: one for the positive class and one for the negative class.
Finally, we can use the prediction scores to make a decision based on the input text. For example, if the positive prediction score is higher than the negative prediction score, we might classify the input text as positive.
if predictions[0] > predictions[1]: print("Positive") else: print("Negative")
By following this step-by-step procedure with the code examples, you can easily use the Hugging Face Inference API to make real-time predictions based on text data using pre-trained NLP models.
Using Hugging Face Inference API for Sentence Embeddings:
Sentence embeddings are numerical representations of text data that are learned using deep learning techniques. These embeddings can be used to measure the similarity between sentences, which is useful for various NLP tasks such as information retrieval, clustering, and classification.
We will explore how to use the Hugging Face Inference API to obtain sentence embeddings using a pre-trained model. Specifically, we will use the example code below to demonstrate how to obtain sentence embeddings using the Hugging Face Inference API:
import requests
def query(payload):
import requests
API_URL = "https://api-inference.huggingface.co/pipeline/feature-extraction/clips/mfaq"
headers = {"Authorization": f"Bearer {api_key}"}
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
def get_embeding(text):
print("Using Huggingface Inference API")
output = query({
"inputs": text,
"options": {"wait_for_model": True}
})
return output
get_embeding("Hello World")
This example code demonstrates how to use the Hugging Face Inference API to obtain sentence embeddings using the CLIPs model. The get_embeding function takes in a string of text as input and returns a JSON object containing the sentence embeddings.
The output of the code is a JSON object containing the sentence embedding for the input text "Hello World". The exact output may vary depending on the specific pre-trained model being used, but it should be a dictionary-like object that contains the sentence embedding as a list of floats. Here's an example output:
{
"last_hidden_state": [
[
-0.07987409853935242,
0.10686787259578705,
-0.0418370364010334,
...
0.023708984166026115,
-0.11434602707624435,
-0.07202731847715378
]
]
}
In this example output, the sentence embedding is contained in the last_hidden_state the key, which contains a list with a single element (since we only passed in a single sentence). The sentence embedding is represented as a list of floats, with each float representing the strength of a particular feature in the sentence.
Using Hugging Face Inference API for NER:
Named Entity Recognition (NER) is a subtask of Natural Language Processing (NLP) that involves identifying and classifying named entities in text into predefined categories such as person names, organizations, locations, and others. NER is used in various applications, including information extraction, machine translation, question answering, and sentiment analysis.
Hugging Face provides a number of pre-trained NER models that can be used for extracting named entities from text data. To use a pre-trained NER model from the Hugging Face Inference API, you can follow these steps:
Install the
requestslibrary in Python usingpip install requests.Get your API key by signing up on the Hugging Face website and creating an API token.
Use the following Python code to load the pre-trained NER model from the Hugging Face Inference API and extract named entities from text data:
import requests
import json
# API endpoint URL
api_url = "https://api-inference.huggingface.co/models/<model-name>"
# API token
api_token = "<your-api-token>"
# Headers
headers = {"Authorization": "Bearer " + api_token}
# Input data
data = {"inputs": "John Smith works at Apple Inc."}
# Send a POST request to the API endpoint with the input data
outputs = requests.post(api_url, headers=headers, json=data)
# Extract named entities from the output
ner_results = outputs.json()[0]["entity_group"]
print(ner_results)
In the code above, replace <model-name> with the name of the pre-trained NER model you want to use, and <your-api-token> with your actual API token.
The input data is provided as a dictionary with a single key "inputs" and the value is the input text to extract named entities from. The requests.post() function is used to send a POST request to the API endpoint with the input data, and the response is stored in the outputs variable. The named entities extracted from the text are then extracted from the output JSON and stored in the ner_results variable.
Using Hugging Face Inference API for QnA:
Question Answering (Q&A) is a natural language processing (NLP) task where a machine is asked a question in natural language, and it provides a relevant answer. With advancements in NLP, models have been developed that can answer complex questions by processing large amounts of text data. Pretrained Q&A models are available on Hugging Face that can be used for various use cases such as chatbots, customer support, and information retrieval.
Using Hugging Face Inference API for Q&A:
Load the pre-trained Q&A model:
url = 'https://api-inference.huggingface.co/models/{MODEL_OWNER}/{MODEL_NAME}' headers = {'Authorization': f'Bearer {API_TOKEN}'} model_id = '{MODEL_OWNER}/{MODEL_NAME}' model_url = url.format(MODEL_OWNER=model_id.split('/')[0], MODEL_NAME=model_id.split('/')[1])Prepare the input data in the required format:
context = 'John lives in New York City. He works at ABC Inc. His office is in Manhattan.' question = 'Where does John work?' data = {"inputs": {"question": question, "context": context}}Send the request to the API to get the answer:
response = requests.post(model_url, headers=headers, json=data) answer = json.loads(response.content.decode('utf-8'))[0]['answer'] print(answer)
In this code, you can replace {MODEL_OWNER} and {MODEL_NAME} with the respective owner and name of the Q&A model that you want to use. You also need to replace {API_TOKEN} with your Hugging Face API token.
Once you have loaded the pre-trained model and provided input data, the API will return the relevant answer for your question based on the context provided. Here's an example output for a question-answering task using the Hugging Face Inference API:
{
"score": 0.912345,
"start": 42,
"end": 54,
"answer": "New York City"
}
In this example, the API has predicted the answer to a question to be "New York City" with a confidence score of 0.912345. The start and end fields indicate the positions of the answer within the input text.
Using Hugging Face Inference API for Summarization:
Summarization is the process of reducing a text to its essential information, providing a concise version that retains the most important parts of the original. Summarization models are widely used in various applications such as news summarization, document summarization, and even chatbot responses. Hugging Face provides pre-trained summarization models that can be easily accessed through their Inference API.
Example Code: Here is an example Python code that uses the Hugging Face Inference API to summarize a text:
import requests
# Replace 'API_TOKEN' with your actual API token
API_TOKEN = 'API_TOKEN'
# Replace 'model_name' with the name of the pre-trained summarization model you want to use
model_name = 'sshleifer/distilbart-cnn-12-6'
# Replace 'text_to_summarize' with the text you want to summarize
text_to_summarize = 'Hugging Face is a company that specializes in Natural Language Processing (NLP). Their Inference API allows developers to easily use pre-trained NLP models to perform various NLP tasks such as Named Entity Recognition (NER), Question Answering (QA), and Summarization. In this example, we will use the Hugging Face Inference API to summarize a text.'
# Define the API endpoint
endpoint = f'https://api-inference.huggingface.co/models/{model_name}'
# Set the request headers
headers = {
'Authorization': f'Bearer {API_TOKEN}',
'Content-Type': 'application/json'
}
# Set the request data
data = {
'inputs': text_to_summarize,
'parameters': {
'max_length': 100,
'min_length': 20,
'do_sample': False
}
}
# Send the request
response = requests.post(endpoint, headers=headers, json=data)
# Get the summarized text from the response
summarized_text = response.json()[0]['summary_text']
# Print the summarized text
print(summarized_text)
In this code, we first specify the API token and the name of the pre-trained summarization model we want to use. We then define the text that we want to summarize. Next, we set the API endpoint and request headers, as well as the data that we want to send to the API. Finally, we send the request and extract the summarized text from the response. The summarized text is then printed to the console.
Scaling NLP Model Deployment with Inference API
The Hugging Face Inference API offers a streamlined way to deploy NLP models quickly and easily, making it possible to scale up to larger datasets more efficiently. Here are some ways the Inference API can speed up NLP model deployment and make it easier to scale up:
Pre-trained models: The Inference API provides access to pre-trained models that have already been fine-tuned on large datasets, allowing you to skip the time-consuming and resource-intensive process of training your models from scratch. This can save a lot of time and resources, especially when working with large datasets.
Cloud-based infrastructure: The Inference API is hosted in the cloud, so you don't need to worry about setting up and maintaining your server infrastructure. This not only saves time and money but also provides more scalability and flexibility for handling large amounts of data.

Streamlined API: The Inference API provides a simple and consistent interface for making API requests to the deployed model, regardless of the underlying model architecture. This makes it easy to integrate NLP models into your applications and scale up to larger datasets as your needs grow.
Fast response times: The Inference API is designed for high performance, with low latency and high throughput. This means that even when processing large datasets, you can get results quickly and efficiently.
Flexible pricing plans: The Inference API offers a variety of pricing plans to suit different use cases and budget constraints. You can choose from pay-as-you-go plans, subscription plans, or enterprise plans, depending on your needs.
Overall, the Inference API provides a convenient and scalable way to deploy NLP models, allowing you to focus on the data and the problem you're trying to solve, rather than the underlying infrastructure. With access to pre-trained models, cloud-based infrastructure, and a streamlined API, you can quickly and easily deploy NLP models to handle larger datasets and more complex natural language processing tasks.
If you're interested in learning more about how to use the Hugging Face Inference API in practice, be sure to check out this YouTube tutorial on the topic:
This tutorial provides a step-by-step guide to using the Inference API to deploy an NLP model and make real-time predictions on text data. You'll learn how to work with the API, how to prepare your data for inference, and how to interpret the results. Whether you're a seasoned NLP practitioner or just getting started with natural language processing, this tutorial is a great resource for learning how to leverage the power of the Hugging Face Inference API.



