PDF Processing: Open Source Tools for PDF to Image Conversion, Text and Table Extraction

PDFs (Portable Document Format) are popular file formats for documents of all kinds, including contracts, manuals, reports, and more. One of the reasons for their popularity is that PDFs preserve the original formatting and layout of the document, making them easy to read and share across different devices and platforms.
If you work with PDFs regularly, you may have encountered challenges such as extracting text or images, working with tables or charts, or merging or splitting documents. Fortunately, there are several open-source tools available that can help streamline these tasks and improve your PDF workflow.
In this blog, we'll explore some of the most useful use cases for working with PDFs using open-source tools, including PDF-to-image conversion, text extraction, table and chart extraction, and merging or splitting documents. Whether you're a student, researcher, or professional, these tools can help you work more efficiently and effectively with PDFs.
PDF to Image Conversion
Converting PDF pages to images can be a useful task for a variety of reasons. One common use case is to extract images from PDFs. PDF documents often contain images or graphics that are important and useful, such as charts, diagrams, or illustrations. By converting the PDF pages to images, you can extract these images and use them for other purposes, such as adding them to a presentation or including them in a report.
Another reason to convert PDF pages to images is for sharing PDF content on social media platforms. Many social media platforms are image-based, meaning that they don't support PDF content natively. By converting PDF pages to images, you can share PDF content on social media platforms as images. For example, you could take a screenshot of a specific page in a PDF document and share it on Instagram or Twitter.
Converting PDF pages to images can also be useful when creating presentations. Many presentation tools, such as PowerPoint or Google Slides, support images but not PDFs. By converting PDF pages to images, you can easily add PDF content to your presentations. For example, you could convert a series of PDF pages to images and then import them into a presentation tool to create a slide deck.
In addition, converting PDF pages to images can be helpful when you need to view PDF content on devices that don't support PDFs. For example, some e-readers or mobile devices may not have built-in PDF readers, but they can display images. By converting PDF pages to images, you can view PDF content on these devices as images instead.
Overall, converting PDF pages to images is a useful task that can help you extract important content from PDFs, share PDF content on social media, create presentations, and view PDF content on devices that don't support PDFs. There are a variety of open-source tools available to perform this task, such as Poppler or ImageMagick, which can convert PDF pages to various image formats like JPEG, PNG, and TIFF.
Open Source Tools to convert PDF to Image:
There are several open-source tools available to convert PDFs to images, such as Poppler and ImageMagick. These tools can be used on the command line, but can also be accessed through Python libraries such as PyPDF2, pdf2image, and Wand. Here's a step-by-step guide to using PyPDF2 and pdf2image to convert PDFs to images:
Install the required libraries: To use PyPDF2 and pdf2image in Python, you need to install them first. You can install them using pip, the Python package installer. Open a terminal or command prompt and enter the following commands:
pip install PyPDF2 pip install pdf2imageImport the required modules: Once the libraries are installed, you need to import the required modules in your Python script. Here's an example of how to do this
import PyPDF2 from pdf2image import convert_from_pathOpen the PDF file: Next, you need to open the PDF file that you want to convert. PyPDF2 provides a PdfFileReader class that can be used to read PDF files. Here's an example of how to open a PDF file:
pdf_file = open('document.pdf', 'rb') pdf_reader = PyPDF2.PdfReader(pdf_file)In this example, "document.pdf" is the name of the PDF file you want to convert.
Convert PDF pages to images: Once you have opened the PDF file, you can use pdf2image to convert the pages of the PDF to images. pdf2image provides a convert_from_path function that takes the path to the PDF file as input and returns a list of PIL (Python Imaging Library) Image objects, one for each page of the PDF. Here's an example of how to use convert_from_path:
pages = convert_from_path('document.pdf')In this example, "document.pdf" is the name of the PDF file you want to convert. The resulting list of "pages" contains one PIL Image object for each page of the PDF.
Note: If you're using Google Colab, you can install Poppler and add it to the system's PATH by running the following commands:
arduinoCopy code!apt-get install poppler-utils import os os.environ['PATH'] += ':/usr/bin/poppler-utils'The first command installs Poppler on the system. The second command adds the path to the Poppler utilities to the system's PATH environment variable so that
pdf2imagecan find them.After running these commands, you can try running your Python code again to convert PDF pages to images using
pdf2image. It should now be able to locate thepdfinfocommand and convert the PDF pages to images.Save the images: Finally, you can save the PIL Image objects as image files using the save method. Here's an example of how to save the images as JPEG files:
for i, page in enumerate(pages): page.save(f'page_{i}.jpg', 'JPEG')
In this example, the images are saved with filenames in the format "page_0.jpg", "page_1.jpg", and so on. The 'JPEG' parameter specifies the image format to use.
Input:
Output:
And that's it! With these steps, you can easily convert PDFs to images using open-source tools and Python.
Text Extraction from PDFs
Extracting text from PDF documents is a valuable use case for several reasons. One of the primary benefits is that it allows you to make PDF content searchable, which can be challenging with documents that only contain scanned images or non-searchable text. By extracting the text from PDF documents, it is possible to create searchable PDFs that make finding and locating specific information much easier.
In addition, extracting text from PDFs can be useful for analyzing PDF content. For example, if you need to analyze the content of a PDF document for text mining or sentiment analysis, extracting the text can be a critical first step. Once the text has been extracted, you can use a variety of tools and techniques to analyze and extract insights from it.
Finally, extracting text from PDFs can be useful for reusing PDF content in other formats. Instead of manually copying and pasting the text, you can extract it automatically and save it in the desired format, such as a Word document or a web page. This can save significant amounts of time and effort, especially for larger PDF documents.
Overall, there are many open-source tools available to extract text from PDFs accurately, even in complex PDF formats with embedded images, fonts, or tables. Extracting text from PDFs can be a crucial step in making PDF content searchable, analyzing PDF content, and reusing PDF content in other formats.
Open Source Tools for Text Extraction from PDFs:
Open-source libraries like PyPDF2, PDFMiner, and Textract can be used to extract text from PDFs using Python code. Here's how to use each of these libraries:
PyPDF2: PyPDF2 is a Python library that can be used to work with PDFs, including extracting text. Here's an example of how to use PyPDF2 to extract text from a PDF:
import PyPDF2 pdf_file = open('dsvds.pdf', 'rb') pdf_reader = PyPDF2.PdfReader(pdf_file) text = '' for page in range(len(pdf_reader.pages)): text += pdf_reader.pages[page].extract_text() print(text)In this example, "document.pdf" is the name of the PDF file you want to extract text from. The
pdf_readerobject reads in the PDF file and theextractText()the method is used to extract the text from each page of the PDF. The extracted text is then concatenated into a single string and printed to the console.For the same pdf file used above the output is as follows:
PDFMiner: PDFMiner is another Python library for working with PDFs, specifically for extracting text and layout information. Here's an example of how to use PDFMiner to extract text from a PDF:
import io from pdfminer.converter import TextConverter from pdfminer.pdfinterp import PDFPageInterpreter from pdfminer.pdfinterp import PDFResourceManager from pdfminer.pdfpage import PDFPage pdf_file = open('dsvds.pdf', 'rb') resource_manager = PDFResourceManager() output_stream = io.StringIO() laparams = None device = TextConverter(resource_manager, output_stream, laparams=laparams) interpreter = PDFPageInterpreter(resource_manager, device) for page in PDFPage.get_pages(pdf_file): interpreter.process_page(page) text = output_stream.getvalue() pdf_file.close() device.close() output_stream.close() print(text)In this example, the PDF file is read and converted to a text stream using the
TextConverterobject. The text is then extracted from each page of the PDF using thePDFPageInterpreterobject. The extracted text is stored in a string variable and printed to the console.Textract: Textract is a Python library that can extract text and data from various file formats, including PDFs. Here's an example of how to use Textract to extract text from a PDF:
import textract text = textract.process('document.pdf', method='pdfminer') print(text)In this example, the
process()method from theextractmodule is used to extract text from the PDF file. Themethodparameter specifies that the PDFMiner engine should be used to extract the text. The extracted text is stored in a string variable and printed to the console.
Example:
Input:

Output:
b'Article\nParallel Structure Deep Neural Network Using CNN\nand RNN with an Attention Mechanism for Breast\nCancer Histology Image Classi\xef\xac\x81cation\n\nHongdou Yao, Xuejie Zhang , Xiaobing Zhou \nSchool of Information Science and Engineering, Yunnan University, Kunming 650091, China;\nyaohongdou@westlake.edu.cn (H.Y.); zhangxj.yn@gmail.com (X.Z.); shengyan0302@gmail.com (S.L.)\n Correspondence: zhouxb@ynu.edu.cn\n\nand Shengyan Liu\n\nReceived: 5 October 2019; Accepted: 26 November 2019; Published: 29 November 2019\n\nAbstract: In this paper, we present a new deep learning model to classify hematoxylin\xe2\x80\x93eosin-stained\nbreast biopsy images into four classes (normal tissues, benign lesions, in situ carcinomas, and invasive\ncarcinomas). Our model uses a parallel structure consist of a convolutional neural network (CNN)\nand a recurrent neural network (RNN) for image feature extraction, which is greatly different from\nthe common existed serial method of extracting image features by CNN and then inputting them\ninto RNN. Then, we introduce a.....
Overall, PyPDF2, PDFMiner, and Textract are all excellent open-source libraries for extracting text from PDFs using Python code. Each library has its strengths and weaknesses, so it's a good idea to try out each one to see which works best for your specific use case.
Extracting Tables from PDF
Extracting tables from PDF documents is a valuable use case for several reasons. One of the primary benefits is that it allows you to easily analyze tabular data that may be difficult to extract manually. For example, if you need to perform statistical or machine learning analysis on data contained in a PDF table, extracting the table can save significant amounts of time and effort.
In addition, extracting tables from PDFs can be useful for converting the tabular data to another format, such as Excel. Instead of manually copying and pasting the data, you can extract it automatically and save it in the desired format. This can be particularly useful if you need to use the data in another application or system.
Extracting tables from PDFs can also be useful for automating data entry tasks. If you receive PDFs with tabular data regularly, extracting the tables can be a useful first step in automating the data entry process. For example, you can use a script to extract the data and import it directly into a database or other system.
Finally, extracting tables from PDFs can help reduce the risk of manual errors. Manually copying and pasting data from PDF tables can be a time-consuming and error-prone process. By extracting the tables automatically, you can reduce the risk of manual errors and save time in the long run.
Open Source Tools to Extract Tables from PDF:
Open-source tools like Tabula and Camelot can be used to extract tables from PDFs using Python. Here's how to use each of these tools:
Camelot: Camelot is a Python library for extracting tables from PDFs. Here's an example of how to use Camelot to extract a table from a PDF file using Python:
Install Camelot by running the following command:
pip install camelot-py[cv] !apt-get install ghostscript python3-tkImport the Camelot library and use the
read_pdf()method to extract the table from the PDF file. For example:pythonCopy codeimport camelot tables = camelot.read_pdf('document.pdf', pages='all') # Extract the first table on the first page table1 = tables[0].df # Extract the second table on the first page table2 = tables[1].df # Save the table as a CSV file table1.to_csv('table1.csv') table2.to_csv('table2.csv')In this example, the
read_pdf()method is used to extract all the tables from the PDF file. The tables are stored in a list ofTableobjects and thedfthe attribute is used to extract the table as a Pandas DataFrame. Finally, the table is saved as a CSV file.
Overall, Tabula and Camelot are both powerful open-source tools for extracting tables from PDFs using Python. Each tool has its strengths and weaknesses, so it's a good idea to try out both to see which works best for your specific use case.
In this blog, we have discussed the various use cases of open-source tools and libraries to work with PDF files in Python. We have explored three main use cases:
Converting PDFs to images: We discussed the benefits of converting PDFs to images and how it can be useful in various scenarios. We explored the use of open-source libraries like Poppler and ImageMagick to convert PDFs to various image formats like PNG, JPEG, and TIFF.
Extracting text from PDFs: We discussed the importance of extracting text from PDFs and how it can be useful for data analysis and text mining. We explored the use of open-source libraries like PyPDF2, PDFMiner, and Textract to extract text from PDFs.
Extracting tables from PDFs: We discussed the challenges involved in extracting tables from PDFs and how they can be useful for data analysis and visualization. We explored the use of open-source tools like Tabula and Camelot to extract tables from PDFs.
Example:
Input:
Output:
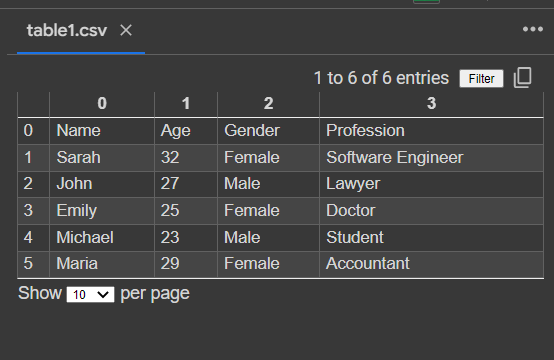
Overall, open-source tools and libraries provide a wide range of options for working with PDFs in Python. Whether you need to convert PDFs to images, extract text from PDFs, or extract tables from PDFs, there are open-source solutions available that can help you get the job done efficiently and effectively.
For similar tasks follow our tutorials:



