YouTube Q&A Chatbot with OpenAI Whisper, Embeddings, ChatGPT & Pinecone

Introduction
In today's world, chatbots have become an essential tool for businesses to interact with their customers. With the advancements in Natural Language Processing (NLP) technology, chatbots are becoming smarter and more efficient. OpenAI, a leading AI research organization, has developed a powerful suite of tools for NLP tasks, including text embeddings and transcription services through their Whisper API.
In this blog, we will explore OpenAi Whisper and its use cases and create a YouTube question-answering chatbot that is integrated with OpenAI's Whisper API for accurate and efficient transcription of audio and video content. We will also leverage OpenAI's text embedding model, ChatGPT, to understand user input and generate relevant responses. Finally, we will use a vector database to find semantically matching content for the given user request.
By the end of this blog, you will have a deep understanding of how to leverage OpenAI's tools to create a powerful chatbot that can answer your queries in a natural and seamless way. So, let's dive in and see how we can create an intelligent chatbot from scratch.
Unboxing OpenAi Whisper
OpenAI has recently unveiled its latest breakthrough in automatic speech recognition (ASR) technology - Whisper. This system is trained on a massive 680,000 hours of multilingual and multitask supervised data sourced from the web, making it a highly accurate and robust transcription tool.
One of the key benefits of Whisper is its ability to transcribe audio with 50% fewer errors than previous models. It is designed to be highly robust to accents, background noise, and technical language, making it an ideal tool for a variety of applications.
Whisper also offers impressive multilingual capabilities, enabling transcription in 99 different languages, as well as translation from those languages into English. It also supports full punctuation, making it even easier to use for various applications.
OpenAi Whisper Use Cases
OpenAI’s Whisper API allows transcription service providers to transcribe audio and video content in multiple languages accurately and efficiently. The API's advanced machine-learning algorithms enable it to transcribe the audio in near real-time, ensuring faster turnaround times.
Another advantage of using the Whisper API is its support for multiple file formats, including MP3, WAV, and FLAC. This feature provides greater flexibility, allowing transcription service providers to work with a wide range of audio and video files.
So now the time has come to do some hands-on coding by exploring a few use-cases of Whisper.
Use Case 1: Subtitle Generation
Step 1
pip install openai-whisper
Install OpenAi Whisper library
Step 2
import whisper
Install the libraries
Step 3
model = whisper.load_model("base")
result = model.transcribe("provide path of your audio file")
print(result["text"])
Load the base model from the whisper library and store it in a variable. Then pass your audio file to the whisper model and it will generate subtitles for the audio using its transcribe method and finally print the transcribed text.
Use Case 2: Audio Language Translation
Whisper is able to perform voice translation from a vast set of languages to English.
Follow Steps 1 and 2 of Whisper Use Case 1
Step 3
model = whisper.load_model("base")
result = model.transcribe("provide path of your audio file", task = 'translate')
print(result["text"])
Load the 'base' model from the whisper library and store it in a variable. Then pass the audio path and task = 'translate' as parameters to the whisper transcribe method and store the returned object in a variable and finally print the translated audio text.
Let's Create A Youtube Question Answering Chatbot
With this app, we can interact with youtube videos in the form of a Q/A chatbot. First, we will generate subtitles of our desired youtube videos and then we will create the embeddings and we will store the embeddings in a vector database(In this case Pinecone). Finally, we will be using Streamlit to create the interface of our chatbot app.
Install The Requirements
openai
pinecone-client
streamlit
streamlit-chat
pandas
numpy
pytube
python-dotenv
Fork the repository from GitHub - https://github.com/PradipNichite/FutureSmart-AI-Blog/tree/main/Youtube%20Q-A%20Chatbot
Open the folder in your local machine and execute the command in your terminalpip install -r requirements
This will install all the libraries required to execute the project.
Create a .env file To Initialize API Keys
openai_key = "Enter your openai key"
pinecone_key = "Provide your pinecone key"
Go to openai.com and get your API key.
Retrieving Content From Youtube Videos
Import The Libraries
# file name youtube_subtitle_gen.py
import openai
import tempfile
import numpy as np
import pandas as pd
from pytube import YouTube, Search
import os
Initialize a dictionary to store the data extracted from youtube videos using pytube and whisper libraries
# file name youtube_subtitle_gen.py
openai.api_key = os.getenv("openai_key")
video_dict = {
"url": [],
"title": [],
"content": []
}
Extracting Audio Content And Transcribing It Using Whisper
# file name youtube_subtitle_gen.py
def video_to_audio(video_URL):
# Get the video
video = YouTube(video_URL)
video_dict["url"].append(video_URL)
try:
video_dict["title"].append(video.title)
except:
video_dict["title"].append("Title not found")
# Convert video to Audio
audio = video.streams.filter(only_audio=True).first()
temp_dir = tempfile.mkdtemp()
variable = np.random.randint(1111, 1111111)
file_name = f'recording{variable}.mp3'
temp_path = os.path.join(temp_dir, file_name)
# audio_in = AudioSegment.from_file(uploaded_file.name, format="m4a")
# with open(temp_path, "wb") as f:
# f.write(uploaded_file.getvalue())
# Save to destination
output = audio.download(output_path=temp_path)
audio_file = open(output, "rb")
textt = openai.Audio.translate("whisper-1", audio_file)["text"]
return textt
video_to_audio: The video_to_audio method takes a youtube URL as an argument. Then we create an object for the Youtube class and name it a video and then we extract the attributes of the video like title, etc.
Next, we convert the video to audio using the below code
audio = video.streams.filter(only_audio=True).first()
and create a temporary directory to store the audio file.
Finally, we extract the subtitles from the audio using openai 'whisper-1" model and save it in a text variable and return the variable.
Saving The Data To A Dataframe
def create_dataframe(data):
df = pd.DataFrame(data)
df.to_csv("history.csv")
s = Search("Youtube video title")
print(len(s.results))
for ele in s.results[0:5:1]:
transcription = video_to_audio(ele.watch_url)
print(transcription)
print("\n\n\n")
video_dict["content"].append(transcription)
create_dataframe(video_dict)
print("Created Dataframe")
create_dataframe: This method takes a dictionary as an argument and converts that dictionary into a pandas data frame and then stores it in a CSV file.
We search for youtube videos using the Search method. Then we loop through each of the videos and generate its subtitles and store them in a dictionary that we had initialized earlier and store all the data in a CSV file.
Transferring Youtube Content To Pinecone
Import The Libraries
import pinecone
import pandas as pd
import openai
import os
Pinecone is a cloud-native vector database that allows us to build high-performance vector search applications. If you are interested to learn more about Pinecone and its use cases then refer to this link - https://docs.pinecone.io/docs/overview
Instantiate Pinecone Index
pinecone.init(api_key=os.getenv("pinecone_key"), environment="us-east-1-aws")
pinecone.create_index(
"demo-youtube-app",
dimension=1536,
metric="cosine",
pod_type="p1"
)
index = pinecone.Index("demo-youtube-app")
print(index.describe_index_stats())
Get Embeddings From The Context
def get_embedding(text):
response = openai.Embedding.create(
input=text,
model="text-embedding-ada-002"
)
return response['data'][0]['embedding']
An embedding is a numerical vector representation of words or phrases in a high-dimensional space. It captures the context and meaning of words by analyzing large amounts of text data using machine learning algorithms.
If you want to know more about embeddings and their use cases then refer to our blog
Save The Embeddings To Pinecone Database
def addData(index,url, title,context):
my_id = index.describe_index_stats()['total_vector_count']
chunkInfo = (str(my_id),
get_embedding(context),
{'video_url': url, 'title':title,'context':context})
index.upsert(vectors=[chunkInfo])
The arguments passed to the method are -
index: pinecone index where we will upsert our data.
url : Youtube video url
title: Youtube video title, we will pass this as metadata so that when we query our database, we can also look into the title and URL of the video to confirm the accuracy of the generated answer
context: Subtitles generated from the video
Finally, with the help of the upsert method, we append data to the vector database.
Answering User Queries From Stored Youtube Content
Import The Libraries
import streamlit as st
import openai
from streamlit_chat import message
import pinecone
import os
import pinecone_utils
Find Context Semantically Similar To User Query
def find_top_match(query, k):
query_em = pinecone_utils.get_embedding(query)
result = index.query(query_em, top_k=k, includeMetadata=True)
return [result['matches'][i]['metadata']['video_url'] for i in range(k)], [result['matches'][i]['metadata']['title']
for i in range(k)], [
result['matches'][i]['metadata']['context']
for i in range(k)]
With this method, we are able to find the most related video based on the input query.
The method takes two parameters - query which is the user query and k which specifies the number of top results to return.
The variable query_em stores the vector representation of the query generated by the openai embedding model.
The index.query() is called to query the vector database. top_k parameter is used to specify the number of most relevant results to return and the includeMetadata parameter specifies whether to include any metadata associated with the search results.
Integrate ChatGPT To Provide Answers
def get_message_history(contexts):
message_hist = [
{"role": "system",
"content": """As a Bot, it's important to show empathy and understanding when answering questions.You are a smart AI who have to answer the question only from the provided context If you
are unable to understand the question and need more clarity then your response should be 'Could you please be
more specific?'. If you are unable to find the answer from the given context then your response should be 'Answer is not present in the provided video' \n"""},
{"role": "system", "content": contexts},
]
return message_hist
def chat(user_query, message, role="user"):
message_history.append({"role": role, "content": f"{var}"})
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=message
)
reply = completion.choices[0].message.content
message_history.append({"role": "assistant", "content": f"{reply}"})
return reply
get_message_history sets up the initial conversation between the user and the AI tutor.
We pass the most similar context passed by the vector database to this method to ensure that answers are only generated from the provided context.
chat takes the message, user_query, and the role as input, makes an API call to chatGPT, and returns the generated response.
Process User Query And Generate Bot Response
# container for chat history
response_container = st.container()
# container for text box
textcontainer = st.container()
with textcontainer:
user_input = get_text()
if st.session_state.past or user_input:
urls, title, context = find_top_match(user_input, 1)
message_history = get_message_history(context[0])
with st.spinner("Generating the answer..."):
response = chat(user_input, message_history)
st.session_state.past.append(user_input)
st.session_state.generated.append(response)
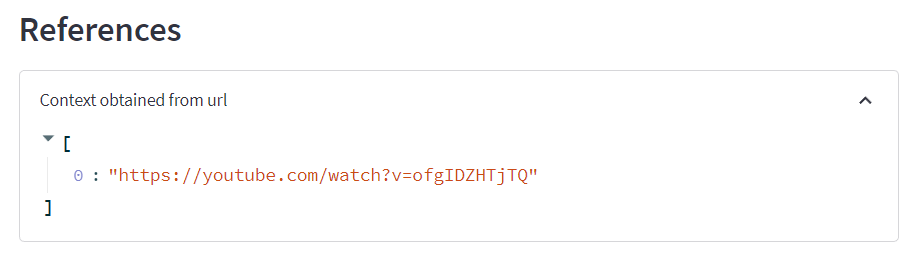
st.subheader("References")
link_expander = st.expander("Context obtained from url")
link_expander.write(urls)
First, the user asks a query and that query gets stored in the use_input variable.
Next, we pass the user query to the find_top_match() method which queries the vector database and provides the document with the highest semantic score.
Then we pass this document and query to chatGPT and its answers to our queries based on the context provided to it.
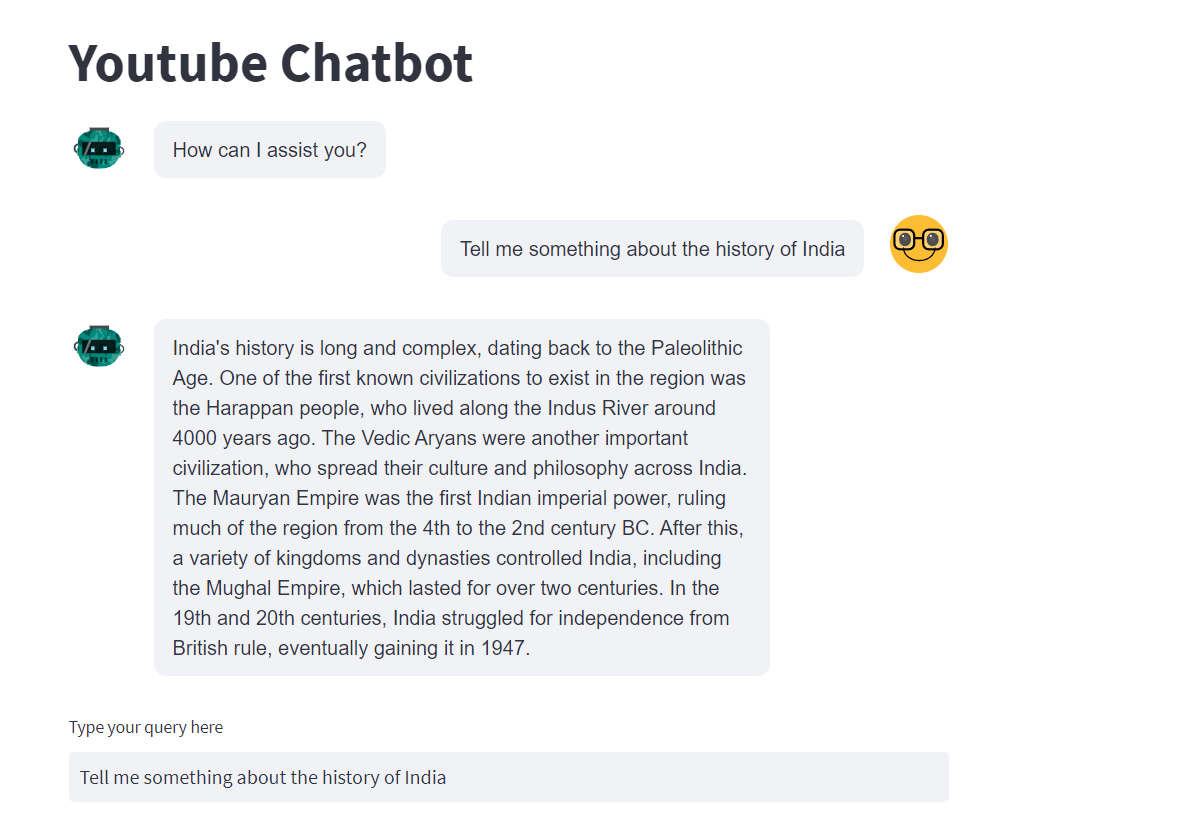
ChatBot In Action
Congratulations, you have made your AI chatbot with semantic search functionalities.
Now it is time to execute your chatbot
Execute the following command in your terminal
streamlit run app.py
Conclusion
In conclusion, building a YouTube Q/A chatbot with OpenAI Whisper, Pinecone vector database, ChatGPT, and OpenAI embeddings was an exciting project that showcases the potential of cutting-edge technologies in natural language processing. By integrating these tools and technologies, we were able to create a chatbot that accurately understands and responds to user queries in real time. Furthermore, with the addition of Streamlit as a frontend, we were able to create an engaging and interactive user interface that enhances the overall user experience. This project is just the beginning of what is possible with advanced NLP techniques and AI technologies, and we look forward to seeing how these innovations will continue to transform the world of conversational AI.
If you are more interested to learn about embeddings and their use cases, then be sure to check out the below YouTube tutorial.
To know more about Vector Database and its applications, refer to the following video
Also, check the video demonstrations of a chatbot integrated with ChatGPT
To learn about more interesting and cool applications of LLMs look into our other Blogs and YouTube channel.
Also, want to learn about the state-of-the-art stuff in AI? Don't forget to subscribe to AI Demos. A place to learn about the latest and cutting-edge tools in AI!



